


Czy Python to dobre narzędzie do automatyzacji procesów biznesowych?
Programowanie
Bez kategorii
Spis treści:
- Kiedy arkusz łapie zadyszkę? Szklany sufit ręcznego „wyklikiwania”
- Budowanie z gotowych klocków: Dlaczego w Pythonie nie piszemy procesów od zera? Ekosystem bibliotek
- Harmonogramowanie zadań
- Przykład – rozbijanie raportu głównego (Report Bursting)
- A dlaczego nie użyć po prostu makr VBA?
- Dlaczego VBA przegrywa to starcie?
- Python – dlaczego jest lepszym narzędziem w tej sytuacji?
- Ciekawostka: Gdy Excel to za mało – przejście na SQL Server
- Wniosek dla managera:
- Podsumowanie: Koniec z cyfrową manufakturą
Arkusze kalkulacyjne to absolutny fundament pracy z danymi w niemal każdej firmie. Są intuicyjne, elastyczne i świetnie sprawdzają się w codziennych zadaniach. Jednak w miarę jak firma rośnie, a tabele puchną od setek tysięcy wierszy, ręczne przetwarzanie informacji staje się wąskim gardłem, które pożera czas Twój i Twojego zespołu.
Aby ratować sytuację i zwiększyć efektywność, często sięgamy po wbudowane mechanizmy automatyzacji – takie jak makra czy narzędzia pokroju Power Query. To solidne „plastry” na lokalne problemy, które pozwalają sprawniej przygotować dane do comiesięcznych raportów.
Przychodzi jednak moment, w którym natrafiamy na szklany sufit.
Gdy nasz proces wymaga płynnego łączenia informacji z wielu różnych systemów, a ilość danych fizycznie wykracza poza techniczne limity arkusza (lub powoduje ciągłe „zamrażanie” programu), standardowe narzędzia biurowe po prostu kapitulują. Potrzebujemy rozwiązania, które działa poza wizualnym interfejsem i nie boi się dużej skali.

W tym miejscu pojawia się język Python, który coraz częściej wykorzystywany jest w analizie danych i automatyzacji procesów. Mimo że Python jest pełnoprawnym językiem programowania, jego zastosowania w świecie korporacyjnym często koncentrują się na rozwiązywaniu tych samych problemów, z którymi na co dzień zmagają się analitycy pracujący w Excelu. Stąd pojawia się pytanie – czy Python faktycznie jest efektywną alternatywą dla dotychczasowych metod pracy w automatyzacji procesów biznesowych? W tym artykule sprawdzimy, jakie konkretne korzyści niesie za sobą wdrożenie Pythona i czy jest on gwarantem wyższej niezawodności w pracy z dużymi zbiorami danych.
Komputer musi nie tylko przetworzyć samą matematykę, ale również wyrenderować widok, odświeżyć piksele i zaktualizować okno aplikacji. Takie podejście staje się krytycznym „wąskim gardłem”, gdy:
- Wolumen informacji drastycznie rośnie i przekracza kilkaset tysięcy wierszy (co często kończy się zacięciem lub zamknięciem pliku).
- Logika biznesowa staje się zbyt skomplikowana, aby zamknąć ją w standardowych, wielokrotnie zagnieżdżonych formułach.
Przechodząc na Pythona, całkowicie eliminujemy ten wizualny balast. Przestajemy obciążać procesor renderowaniem widoku arkusza, a całą operację wykonujemy bezpośrednio i bezszelestnie w pamięci operacyjnej komputera.
Kiedy arkusz łapie zadyszkę? Szklany sufit ręcznego „wyklikiwania”
Główna różnica pomiędzy wykorzystaniem Excela a Pythona polega na zmianie sposobu interakcji z danymi. W klasycznym arkuszu nasze działanie opiera się na manualnym „wyklikiwaniu” – zaznaczamy komórki, przeciągamy formuły i ręcznie sterujemy opcjami w wizualnym interfejsie. Widzimy dane bezpośrednio na ekranie, co daje poczucie kontroli i jest niezwykle intuicyjne. Problem polega na tym, że każda taka operacja w wizualnym interfejsie potężnie obciąża program. Komputer musi nie tylko przetworzyć samą matematykę, ale również wyrenderować widok, odświeżyć piksele i zaktualizować okno aplikacji. Takie podejście staje się krytycznym „wąskim gardłem”, gdy:
- Wolumen informacji drastycznie rośnie i przekracza kilkaset tysięcy wierszy (co często kończy się zacięciem lub zamknięciem pliku).
- Logika biznesowa staje się zbyt skomplikowana, aby zamknąć ją w standardowych, wielokrotnie zagnieżdżonych formułach.

Wykorzystując Pythona, eliminujemy konieczność wizualnej reprezentacji danych w trakcie ich przetwarzania, co przy dużej ilości informacji diametralnie zwiększa wydajność. Skrypt działa w tle, wykonując operacje bezpośrednio w pamięci operacyjnej, dzięki czemu błyskawicznie przeliczamy zbiory, które w Excelu spowodowałyby „zamrożenie” aplikacji. Nie ogranicza nas już sztywny limit wierszy, a jedynie dostępna moc obliczeniowa komputera. Pozwala to na swobodną pracę z całymi bazami danych, bez potrzeby sztucznego dzielenia ich na mniejsze pliki.
Budowanie z gotowych klocków: Dlaczego w Pythonie nie piszemy procesów od zera? Ekosystem bibliotek
W środowisku korporacyjnym kluczowa jest również optymalizacja czasu pracy, co oznacza brak konieczności implementowania standardowych procesów od podstaw. Siła Pythona wynika z jego rozbudowanych bibliotek – gotowych, zoptymalizowanych modułów, dedykowanych do realizacji konkretnych zadań biznesowych. Dzięki nim, zamiast tworzyć tysiące linii autorskiego kodu, wykorzystujemy sprawdzone i stabilne rozwiązania za pomocą zaledwie kilku komend. Przykładowo:
- Pandas pozwala na obróbkę milionów wierszy w ułamku sekundy, oferując możliwości agregacji i filtracji zbliżone do języka SQL, ale przy zachowaniu elastyczności znanej z Excela.
- Openpyxl / XlsxWriter służą do pełnej integracji z plikami pakietu Office. Dzięki nim możemy w Pythonie zarówno odczytać dane z arkuszy, jak i wygenerować gotowy, sformatowany raport zapisany w pliku .xlsx, dostosować style komórek, a nawet tworzyć wykresy.
- Selenium/Playwright umożliwiają sterowanie przeglądarką internetową, naśladowanie ruchów użytkownika i pobieranie danych ze stron, które nie posiadają interfejsu API.
- Outlook/Gmail API pozwalają na pełną automatyzację komunikacji mailowej. Umożliwiają stworzenie skryptu, który np. wyśle spersonalizowane raporty do listy odbiorców. Dzięki nim Python może również „czuwać” na skrzynce, monitorując przychodzące wiadomości i reagując na nie w odpowiedni sposób – np. pobierając dane z załączonych faktur i na ich podstawie aktualizować raporty w Excelu.
Harmonogramowanie zadań
Ogromną zaletą tego podejścia jest również możliwość całkowitego uniezależnienia procesów od fizycznej obecności pracownika. Skrypty w języku Python doskonale integrują się z systemowym Harmonogramem Zadań (Windows Task Scheduler) czy usługami chmurowymi. W praktyce oznacza to, że raporty, które dotychczas wymagały od nas ręcznego uruchomienia i odświeżenia danych, mogą być generowane w pełni automatycznie. Dzięki temu, w momencie rozpoczęcia dnia pracy, gotowe zestawienie będzie na nas czekać w skrzynce mailowej.
Przykład – rozbijanie raportu głównego (Report Bursting)
Opis teoretyczny to jedno, ale prawdziwą siłę narzędzia poznaje się w praktyce. Dlatego nasz przykład zobrazuje różnicę w podejściu do automatyzacji: porównamy tradycyjne metody (Excel, VBA, Power Query) z możliwościami skryptów Pythona. Na warsztat bierzemy proces, który jest zmorą wielu działów raportowania – konieczność podzielenia jednego, głównego zbioru danych na dziesiątki indywidualnych plików i wysłanie ich do odpowiednich odbiorców.
Centrala firmy generuje jeden duży plik ze sprzedaży (np. 100 000 wierszy), obejmujący wyniki handlowców z całego kraju. Zadanie polega na tym, aby każdy z 50 Kierowników Regionalnych otrzymał plik Excel zawierający wyłącznie dane ze swojego regionu. Ręczne filtrowanie, kopiowanie i zapisywanie 50 osobnych plików to kilka godzin pracy i ogromne ryzyko pomyłki (np. wysłanie danych Regionu Północ do kierownika z Południa – co stanowi naruszenie zasad bezpieczeństwa danych).
Fragment danych z pliku głównego:

Gdybyśmy mieli wykonać pracę manualnie w Excelu, musielibyśmy:
- Otworzyć plik główny.
- Włączyć filtr na Kierownika pierwszego – Anna Kowalska.
- Skopiować dane.
- Wkleić do nowego skoroszytu.
- Zapisać jako „Raport_Anna_Kowalska.xlsx”.
- Powtórzyć to 40 razy.
- Ręcznie wysłać 40 maili, pilnując, by nie wysłać danych Regionu 1 do kierownika Regionu 2 (ryzyko RODO/wycieku danych!).
A dlaczego nie użyć po prostu makr VBA?
Naturalnym odruchem w środowisku Excela jest próba automatyzacji tego procesu za pomocą wbudowanego języka VBA (Visual Basic for Applications). Przez lata było to domyślne, „tradycyjne” rozwiązanie w korporacjach. Jednak w konfrontacji z dzisiejszymi standardami bezpieczeństwa i skalą danych, technologia ta coraz częściej okazuje się mniej efektywną opcją.
Dlaczego VBA przegrywa to starcie?
Choć teoretycznie napisanie makra jest skuteczne, w praktyce – przy dużej skali operacji i nowoczesnym środowisku IT – rozwiązanie to szybko ujawnia swoje archaiczne ograniczenia:
- Niestabilność wizualna: VBA działa „na żywo” na otwartym arkuszu. Przy pętli powtarzanej 50 czy 100 razy, Excel często „miga”, zawiesza się lub wyrzuca błąd „Brak odpowiedzi”, jeśli użytkownik przypadkiem kliknie myszką w trakcie procesu.
- Problemy z bezpieczeństwem: Działy IT coraz częściej domyślnie blokują pliki z rozszerzeniem .xlsm lub pliki z makrami pochodzące z sieci/maila. Przesłanie takiego narzędzia do innego działu często kończy się czerwoną belką „Makra zostały zablokowane”.
- Trudna obsługa błędów: Jeśli w 49. pliku wystąpi błąd (np. niestandardowy znak w nazwie regionu), VBA często przerywa działanie, zostawiając nas z połowicznie wykonaną pracą i otwartymi w tle procesami Excela, które trzeba wyłączać w Menedżerze Zadań.
- Problemy z wysyłką e-mail: Makra VBA są technologicznie uzależnione od lokalnie zainstalowanej aplikacji Outlook, co w nowoczesnym, chmurowym środowisku pracy staje się poważnym ograniczeniem:
-
- Brak elastyczności: Jeśli Twoja firma korzysta z poczty przez przeglądarkę (np. Gmail, Office 365 Web) lub innego klienta (np. Thunderbird), makro po prostu nie zadziała. VBA nie potrafi „kliknąć” w przycisk „Wyślij” na stronie www.
- Blokady bezpieczeństwa: Nawet posiadanie desktopowego Outlooka nie gwarantuje sukcesu. Zabezpieczenia Microsoftu często interpretują próbę seryjnej wysyłki przez makro jako aktywność wirusa, wyświetlając przy każdej wiadomości okno: „Program próbuje wysłać wiadomość w Twoim imieniu. Czy zezwolić?”. Konieczność ręcznego klikania „Tak” 50 razy całkowicie przekreśla sens automatyzacji.
Python – dlaczego jest lepszym narzędziem w tej sytuacji?
Zastosowanie Pythona zmienia ten proces w operację czysto matematyczną, wykonywaną poza interfejsem graficznym.
- Szybkość i stabilność: Skrypt nie otwiera Excela wizualnie. Wczytuje dane do pamięci RAM, dzieli je na 50 wirtualnych tabel i zrzuca na dysk w ułamku czasu, jaki potrzebuje Excel i VBA. Nie ma ryzyka „kliknięcia i zawieszenia”, bo proces dzieje się w tle.
- Czystość kodu: To, co w VBA zajęłoby 100 linii kodu, w Python, wykorzystując bibliotekę Pandas, zamyka się w kilku czytelnych linijkach. Filtrowanie danych to jedna prosta komenda.
- Nowoczesna integracja: Gdy pliki są już podzielone, Python może natychmiast, w tym samym skrypcie, połączyć się z serwerem pocztowym (nawet przy użyciu nowoczesnych zabezpieczeń OAuth2/MFA, z czym VBA ma ogromny problem) i rozesłać spersonalizowane wiadomości do odpowiednich osób.
W tym scenariuszu Python nie jest tylko „trochę szybszy”. Jest rozwiązaniem innej klasy – zmienia ręczną manufakturę w przemysłową linię produkcyjną raportów.
Najlepiej świadczy o tym sam kod – zwięzły, czytelny i mieszczący się na jednym ekranie:
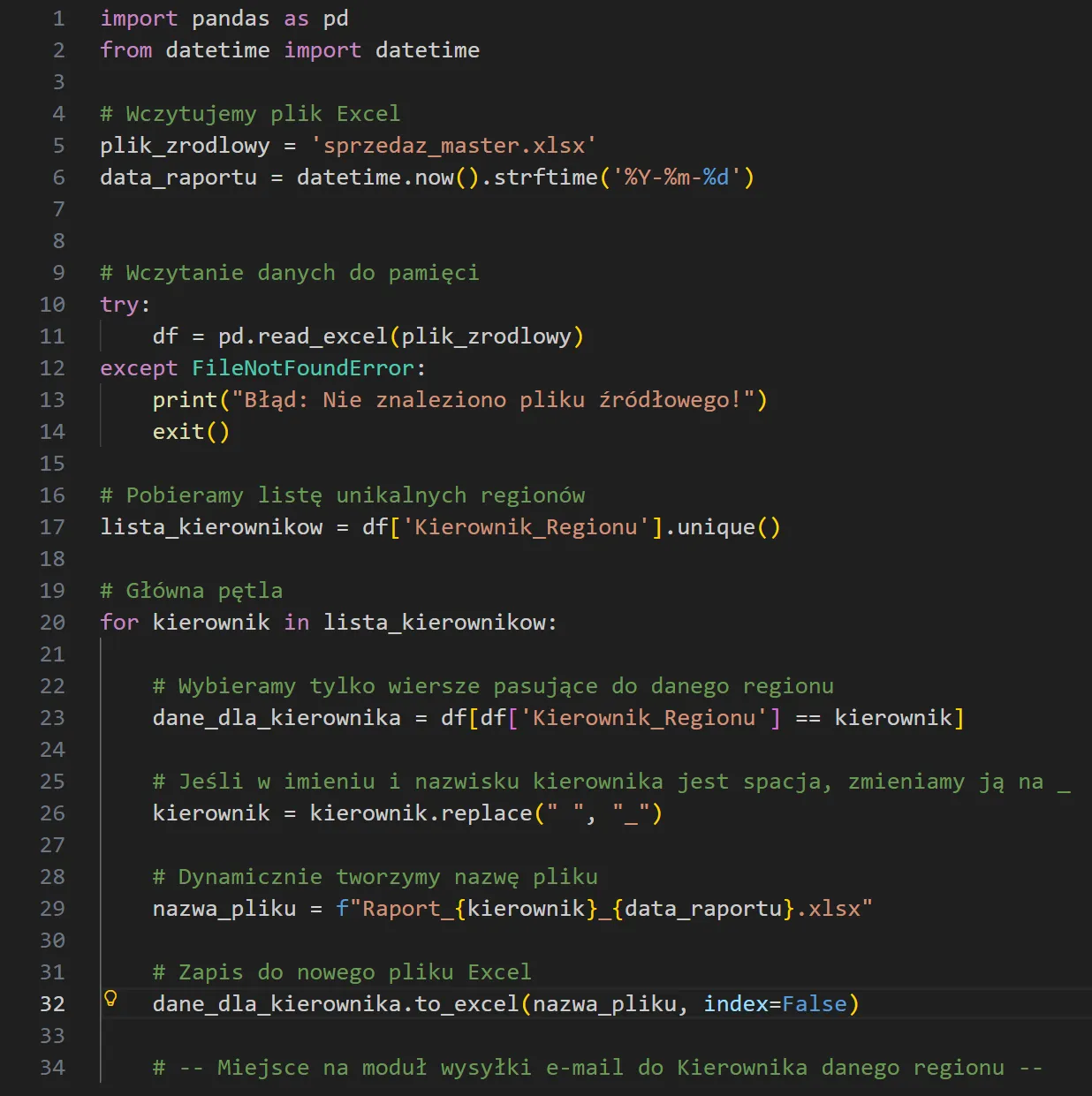
Zwróć uwagę na ostatnią, zakomentowaną linię w powyższym kodzie.
W tym przykładzie celowo skupiliśmy się wyłącznie na podziale i zapisie plików, aby zachować przejrzystość skryptu.
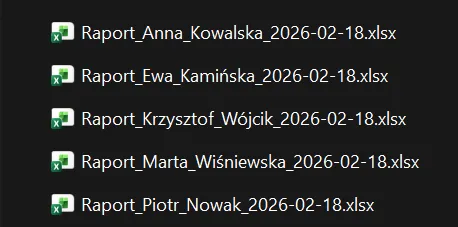
Po uruchomieniu skryptu, operacja wykonuje się w tle, wykorzystując pamięć operacyjną komputera. Nie obserwujemy przy tym otwierania się okien Excela ani żadnej ingerencji w interfejs graficzny systemu.
Wystarczy zajrzeć do katalogu, w którym pracujemy. W ciągu kilku sekund pojawi się tam komplet wygenerowanych raportów cząstkowych:
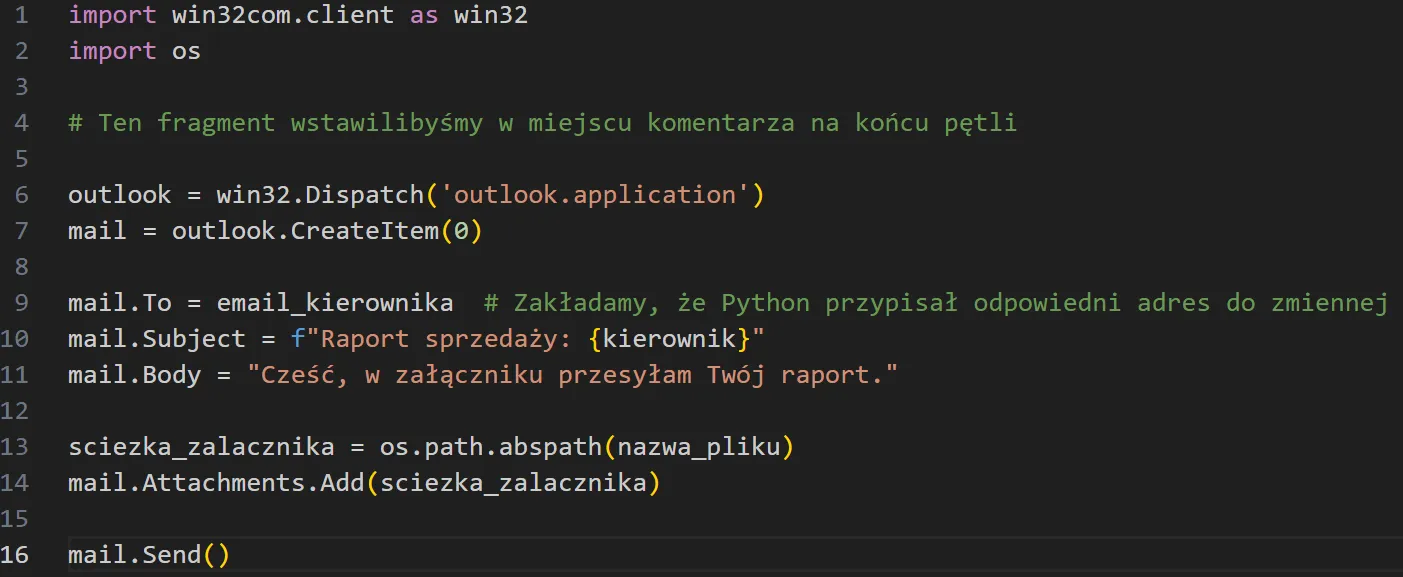
Gdybyśmy chcieli jednak, żeby Python mógł samodzielnie rozesłać raporty, musielibyśmy dostarczyć mu bazę adresatów (np. osobny plik Excel, w którym przypisalibyśmy adresy e-mail do konkretnych kierowników).
Gdy dysponujemy już adresem, przypisanym do zmiennej, wysłanie raportu jest już bardzo prostym zadaniem. Wystarczy użyć np. biblioteki win32com, która pozwala Pythonowi automatycznie otworzyć Outlooka, stworzyć nową wiadomość, załączyć odpowiedni plik i wysłać go do właściwego kierownika:
Ciekawostka: Gdy Excel to za mało – przejście na SQL Server
W miarę rozwoju firmy dane często przenoszone są z plików Excel do profesjonalnych baz danych, takich jak SQL Server. Dla programisty VBA taka zmiana to zazwyczaj „małe trzęsienie ziemi” – wymaga napisania od nowa ogromnych fragmentów kodu odpowiedzialnych za połączenie (ADODB), obsługę rekordów (Recordsets) i żmudne przepisywanie danych do komórek.
W Pythonie ta zmiana jest niemal nieodczuwalna. Dzięki bibliotece Pandas i silnikowi SQLAlchemy, baza danych jest traktowana niemal identycznie jak arkusz Excela.
Dlaczego Python wygrywa z VBA w starciu z bazami danych?
- Brak „śmieciowego” kodu: W VBA musisz ręcznie otwierać połączenie, dbać o jego zamknięcie i pilnować typów danych. W Pythonie załatwia to jedna linijka.
- Odporność na skalę: Python nie „wyłoży się” na milionie wierszy tak szybko jak Excel. Dane z SQL lądują w pamięci RAM, gdzie operacje na nich są tysiące razy szybsze.
- Czystość logiczna: Zmieniamy tylko źródło danych. Cała reszta skryptu (filtrowanie, podział na regiony, wysyłka maili) pozostaje dokładnie taka sama.
Jak wygląda zmiana w praktyce?
Wystarczy podmienić blok wczytywania danych. Cała reszta skryptu nawet nie zauważy zmiany. Zamiast czytać plik z dysku:

Podłączamy się pod serwer i wysyłamy bezpośrednie zapytanie do bazy danych:
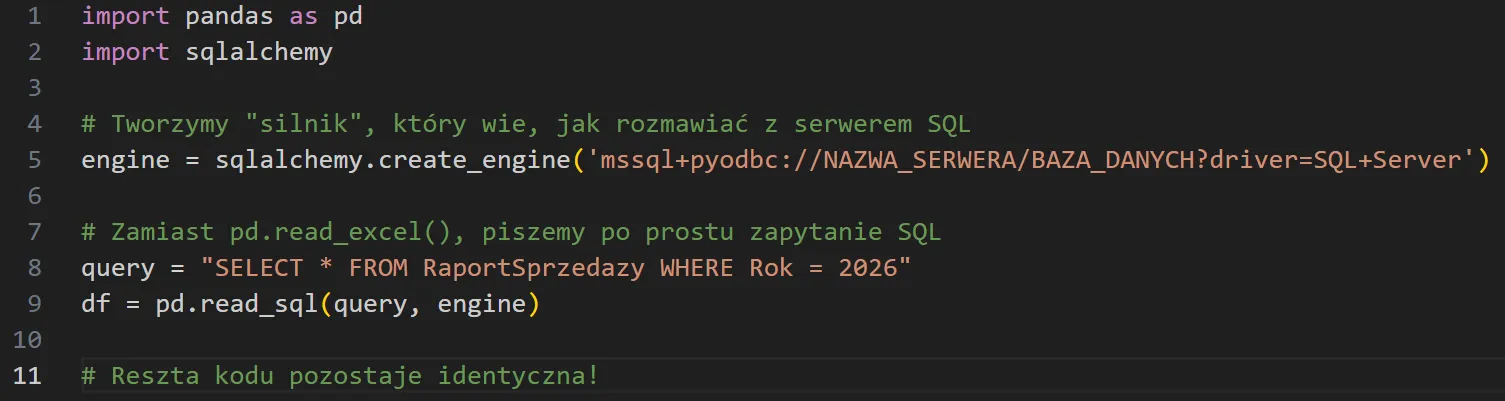
Reszta kodu pozostaje identyczna.
Dlaczego tak się dzieje? Tajemnica tkwi w zmiennej df (obiekt DataFrame z biblioteki Pandas). Dla Pythona nie ma absolutnie żadnego znaczenia, czy ta wirtualna tabela w pamięci RAM została zasilona z pliku .xlsx, czy z potężnej bazy SQL.
Gdy dane znajdą się już wewnątrz df, cała napisana przez Ciebie wcześniej logika biznesowa – filtrowanie po regionach, podział na oddzielne pliki i wysyłka przez Outlooka – zadziała bezbłędnie, linijka po linijce.
Wniosek dla managera:
Wybierając Pythona, nie tylko rozwiązujemy dzisiejszy problem z raportami, ale budujemy rozwiązanie „przyszłościowe” – skalowalną infrastrukturę danych. W świecie VBA próba wyjścia poza arkusz Excela na rzecz profesjonalnej bazy danych to droga przez mękę. W Pythonie to naturalny etap ewolucji.
- Gotowość na „Big Data”
Excel ma swój „szklany sufit” – nieco ponad milion wierszy. Dla dynamicznie rosnącej firmy to bariera nie do przejścia. Python nie ma takich limitów. Jeśli nasz zespół operuje dziś na tysiącach rekordów, a jutro – dzięki nowym rynkom – zacznie na dziesiątkach milionów, ten sam skrypt poradzi sobie z zadaniem. Zmieniamy tylko silnik przechowujący dane, a logika biznesowa pozostanie nienaruszona.
- Łatwa migracja: Od arkusza po Hurtownie Danych (Cloud)
Dzisiaj naszym źródłem jest plik .xlsx na dysku. Jutro może to być profesjonalna Baza lub Hurtownia Danych (np. Snowflake, Google BigQuery czy Amazon Redshift).
- W VBA: Przejście na takie rozwiązanie to projekt informatyczny na wiele tygodni i pisanie kodu od zera.
- W Pythonie: To zmiana zaledwie kilku parametrów połączenia. Python jest „językiem ojczystym” chmury, więc integracja z nowoczesnymi systemami klasy korporacyjnej trwa godziny, a nie miesiące.
- Koniec z „dzikim IT” i budowa trwałego know-how
Wybór Pythona to przejście z kultury doraźnych „protez” (często spotykanych w VBA) na kulturę profesjonalnych rozwiązań systemowych. Pozwala to uniknąć jednej z największych bolączek korporacyjnych: uzależnienia od jednego pracownika.
- Eliminacja ryzyka „osieroconych makr”: Wiele firm funkcjonuje dzięki skomplikowanym makrom napisanym lata temu przez osoby, których już nie ma w zespole. Nikt nie wie, jak one działają, a każda próba ich poprawy grozi paraliżem pracy. Python, dzięki swojej czytelności i standardom dokumentowania, eliminuje ten problem.
- Wspólny język z działem IT: Python jest standardem rynkowym. Kod napisany przez analityka w tym języku jest zrozumiały dla programisty czy inżyniera danych. Dzięki temu proces przekazania małego skryptu do profesjonalnego wdrożenia przez dział IT (tzw. produktywizacja) trwa dni, a nie miesiące.
- Budowa uniwersalnych kompetencji: Inwestując w Pythona, nie uczymy ludzi obsługi „przycisku w Excelu”. Uczymy ich logicznego myślenia o danych, które mogą wykorzystać w dowolnym miejscu firmy – od marketingu, przez logistykę, aż po zaawansowany controlling.
Podsumowanie: Koniec z cyfrową manufakturą
Wprowadzenie Pythona do naszych codziennych procesów to nie jest zwykła aktualizacja narzędzi roboczych. To całkowita zmiana paradygmatu pracy z danymi, to znacznie więcej niż tylko kolejny, techniczny „trik” na przyspieszenie pracy arkuszy kalkulacyjnych.
Do tej pory działaliśmy w modelu cyfrowej manufaktury – każdy raport był żmudnie i ręcznie „lepiony”, co naturalnie generowało wąskie gardła i potęgowało ryzyko ludzkiego błędu. Przechodząc na kod, nasza firma zyskuje w pełni autonomiczną linię produkcyjną. Proces staje się w 100% powtarzalny, błyskawiczny i całkowicie odporny na zmęczenie materiału.

Co zyskuje Biznes? (Perspektywa Managera) Koniec z kulturą „czarnych skrzynek” – skomplikowanych makr, których działania nikt poza ich twórcą nie rozumie. Python pozwala zbudować przejrzysty, modularny ekosystem, który jest łatwy do audytu i dalszej rozbudowy przez dowolnego specjalistę na rynku. To inwestycja w stabilność: procesy stają się niezależne od interfejsu Excela, a system nie dławi się przy wzroście ilości przetwarzanych danych. Z każdym nowym rekordem ten automat zarabia na siebie szybciej, gwarantując spójność i bezpieczeństwo informacji.
Co zyskuje Pracownik? (Perspektywa Specjalisty) Dla analityka czy kontrolera finansowego nauka Pythona to bilet do pierwszej ligi rynku pracy. Przestajemy być „operatorem arkusza”, który spędza godziny na kopiowaniu komórek, a stajemy się architektem procesów.
- Odzyskujemy czas: Nudne, powtarzalne zadania przejmuje skrypt, a my możemy skupić się na wnioskowaniu i strategii.
- Budujemy unikalne kompetencje: Stajemy się pomostem między biznesem a IT. To umiejętność, która drastycznie podnosi naszą wartość rynkową i otwiera drzwi do ról takich jak Data Analyst czy Business Intelligence Developer.
W tym scenariuszu wygrywają wszyscy: firma otrzymuje niezawodny silnik analityczny, a pracownik zyskuje narzędzia, które uwalniają go od rutyny i napędzają rozwój własnej kariery.

ChatGPT, Microsoft 365 Copilot, Google Gemini – porównanie najpopularniejszych aplikacji AI

Lovable – co to za aplikacja i do czego służy?

Funkcja T w Excelu — małe narzędzie, które pomaga utrzymać porządek w danych

Wprowadzenie do Machine Learning: Co to jest i dlaczego warto się tym zainteresować
