


Ile czasu potrzeba, żeby nauczyć się Pythona do pracy z danymi?
Analityka danych
Bez kategorii
Spis treści:
Wstęp
W dzisiejszym środowisku biznesowym bardzo często potrzebujemy efektywnych narzędzi do analizy i przetwarzania coraz większych zbiorów danych. Tradycyjne metody pracy, takie jak standardowe arkusze kalkulacyjne, z czasem stają się niewydajne i napotykają ograniczenia przy bardziej złożonych, powtarzalnych operacjach. W takich sytuacjach optymalnym i wysoce skalowalnym wyborem staje się Python – język programowania powszechnie wykorzystywany w obszarze Data Science (nauki o danych).
Rozpoczynając proces edukacji w tym kierunku, łatwo zagubić się w natłoku materiałów edukacyjnych i trudnych do weryfikacji szacunkach dotyczących czasu nauki. W tym artykule postaramy się przeanalizować i określić, ile czasu w rzeczywistości może być potrzebne do opanowania narzędzi do analizy danych opartych na języku Python. Krok po kroku pokażemy, jak mądrze zaplanować naukę, aby nie tracić czasu na zbędną teorię i skupić się na umiejętnościach, które faktycznie wykorzystamy w codziennej pracy analitycznej.

Brak doświadczenia w językach programowania
Zanim jednak przejdziemy do omawiania konkretnych narzędzi analitycznych, musimy zwrócić uwagę na podstawy programowania, które są niezbędne do dalszej nauki. Brak wcześniejszego doświadczenia technicznego sprawia, że rzetelne poznanie tych mechanizmów wymaga czasu, jednak jest to etap kluczowy, by w przyszłości pracować samodzielnie i świadomie. Zrozumienie bazowej logiki działania języka Python sprawi, że późniejsza praca z ogromnymi zbiorami danych stanie się po prostu intuicyjna i płynna. Aby móc efektywnie tworzyć pierwsze skrypty, musimy najpierw przyswoić kilka kluczowych pojęć:
- Zmienne i typy danych: To nasze podstawowe kontenery w pamięci komputera, których przechowujemy konkretne informacje (np. wartości tekstowe, liczby czy daty), aby móc z nich korzystać i modyfikować je w dalszej części kodu.
- Instrukcje warunkowe (If/Else): Mechanizm pozwalający skryptom podejmować zautomatyzowane decyzje na podstawie zdefiniowanych przez nas reguł – działający bardzo podobnie do znanej z arkuszy kalkulacyjnych funkcji JEŻELI.
- Pętle (For/While): Konstrukcje służące do automatycznego powtarzania tej samej operacji. Dzięki nim możemy błyskawicznie przetworzyć tysiące wierszy danych bez konieczności ręcznego powielania poleceń.
- Struktury danych (Listy i Słowniki): Sprawdzone sposoby na uporządkowane przechowywanie wielu powiązanych ze sobą informacji w jednym miejscu, co drastycznie ułatwia ich grupowanie, filtrowanie i przeszukiwanie.
- Funkcje: Wydzielone, gotowe do ponownego użycia bloki kodu, które wykonują jedno konkretne zadanie, dzięki czemu zachowujemy porządek i unikamy wielokrotnego przepisywania tych samych instrukcji.
- Programowanie obiektowe (OOP): Powszechny standard pisania kodu, w którym modelujemy rzeczywiste elementy jako „obiekty” posiadające własne cechy i zachowania, co jest niezbędne do sprawnego poruszania się po zaawansowanych bibliotekach analitycznych.
A co, jeśli znamy już inny język programowania?
Przejście na Pythona dla osób, które miały już styczność z innymi technologiami – takimi jak Java, C++ czy JavaScript – jest procesem błyskawicznym. Skoro rozumiemy już logikę działania pętli, funkcji czy instrukcji warunkowych, nie musimy uczyć się programowania od nowa. Pozostaje nam jedynie przyswojenie nowej składni tego języka. W praktyce opanowanie podstawowych komend Pythona i swobodne poruszanie się w nowym środowisku to kwestia zaledwie kilku dni.
Główną różnicą i ogromną zaletą tego języka jest jego uproszczona, minimalistyczna konstrukcja. Python został zaprojektowany tak, aby był maksymalnie czytelny i przypominał naturalny język angielski. Zrezygnowano w nim z wielu nadmiarowych znaków, takich jak obowiązkowe średniki na końcu każdej linii czy konieczność sztywnego określania typów danych przy tworzeniu zmiennych.
Aby najlepiej to zilustrować, spójrzmy na proste zestawienie kodów w językach Java i Python. Załóżmy, że chcemy zapisać w pamięci wiek użytkownika jako liczbę całkowitą, a następnie wyświetlić z nią krótki komunikat na ekranie.
Kod w języku Java:

Ten sam kod w języku Python:
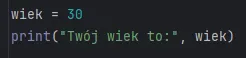
Jak widać na powyższym zestawieniu, kod w Pythonie jest znacznie uproszczony i pozbawiony technicznego narzutu, takiego jak budowanie klas czy ręczne definiowanie typów zmiennych. Mimo tej wizualnej różnicy, pod spodem środowisko to opiera się dokładnie na tych samych, uniwersalnych fundamentach programistycznych, co pozostałe języki. Zmieniamy po prostu sposób zapisu poleceń na krótszy i bardziej czytelny. Właśnie ten brak rygorystycznych reguł składniowych powoduje, że próg wejścia w analizę danych dla osób z innych środowisk technologicznych jest niemal zerowy, a samo pisanie kodu staje się procesem niezwykle intuicyjnym.
Biblioteki w Python
Kiedy mamy już opanowane absolutne fundamenty języka, stajemy przed ważnym pytaniem: co dalej? Świat Pythona jest ogromny, a prawdziwa siła tego środowiska w kontekście analizy danych nie leży w samym czystym kodzie, lecz w tzw. bibliotekach. Są to pakiety gotowych, zoptymalizowanych rozwiązań i funkcji. Zamiast tworzyć od zera skomplikowany algorytm, np. łączenie plików, po prostu ładujemy takie gotowe narzędzie i wywołujemy je jedną, krótką komendą.
Ekosystem Pythona oferuje tysiące różnorodnych bibliotek, jednak próba przyswojenia ich wszystkich jednocześnie to prosta droga do zniechęcenia. W praktyce biznesowej opanowanie zaledwie kilku kluczowych pozwala zrealizować 90% codziennych zadań. Oto optymalna mapa drogowa, na której najlepiej oprzeć swój proces nauki:
- Pandas (Przetwarzanie i porządkowanie): To absolutne serce analityki w Pythonie. Można o nim myśleć jak o potężnym, zautomatyzowanym arkuszu kalkulacyjnym, który obsługujemy za pomocą kodu. Służy do wczytywania ciężkich plików (od standardowych Exceli, przez pliki CSV, po bezpośrednie połączenia z bazami danych), radzenia sobie z brakującymi wartościami, filtrowania i łączenia wielu źródeł w jeden spójny zestaw.
- OS oraz Pathlib (Automatyzacja plików): Zanim zaczniemy analizę, musimy sprawnie zarządzać danymi na dysku. Biblioteka os to klasyczne narzędzie, które pozwala naszemu programowi „rozglądać się” po folderach, tworzyć nowe katalogi czy automatycznie pobierać listy nazw plików do przetworzenia. Jeśli jednak szukamy bardziej nowoczesnego i intuicyjnego podejścia, warto sięgnąć po pathlib. To nowszy standard, który traktuje ścieżki do plików jak obiekty, co czyni nasz kod czytelniejszym i mniej podatnym na błędy przy pracy na różnych systemach operacyjnych.
- NumPy (Fundament matematyczny): Wysokowydajny silnik matematyczny, który odpowiada za pracę na ogromnych zbiorach liczbowych i pozwala błyskawicznie przeliczać setki tysięcy rekordów. Choć w codziennym raportowaniu rzadziej wywołujemy jego funkcje bezpośrednio, musimy rozumieć jego działanie, ponieważ to na nim opiera się szybkość biblioteki Pandas.
- Matplotlib i Seaborn (Wizualizacja wyników): Same, poprawnie przefiltrowane tabele z liczbami to często za mało, by wyciągnąć szybkie wnioski biznesowe – potrzebujemy przejrzystego obrazu. Matplotlib to bazowa, niezwykle elastyczna biblioteka pozwalająca narysować niemal każdy rodzaj wykresu. Z kolei Seaborn to jej nowoczesna nakładka, która przy użyciu zaledwie kilku linijek kodu generuje estetyczne i profesjonalne wizualizacje statystyczne, od razu gotowe do wklejenia w menedżerską prezentację.

Co ważne, rozpoczęcie pracy z tymi narzędziami nie wymaga od nas skomplikowanej konfiguracji. Jeśli nie mamy ich jeszcze na swoim komputerze, wystarczy pobrać gotową paczkę, wpisując w systemowej konsoli jedną, standardową komendę – np. pip install pandas. Narzędzie o nazwie pip (wbudowane w Pythona) samo połączy się z internetem, pobierze pliki i przygotuje je do pracy, niezależnie od tego, w jakim programie piszemy później nasz kod.
Gdy biblioteka jest już zainstalowana, uzyskanie do niej dostępu wewnątrz naszego pliku jest bardzo proste. Na samym początku skryptu używamy polecenia import, przypisując jednocześnie pobranej paczce krótki, powszechnie używany skrót (tzw. alias, np. pd dla Pandas):
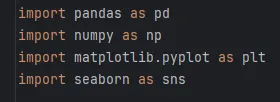
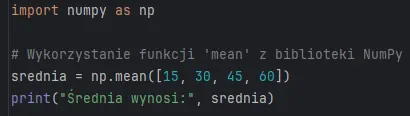
Od tego momentu odwołanie się do nazwy, którą właśnie przypisaliśmy, daje nam pełen dostęp do potężnych funkcjonalności pakietu. Wystarczy użyć naszego skrótu, który przypisaliśmy do konkretnej biblioteki i wywołać konkretne narzędzie – na przykład błyskawiczną funkcję liczącą średnią matematyczną z podanych wartości:
💡 Ciekawostka:
Python często bywa określany w środowisku IT jako język stosunkowo wolny w porównaniu do innych technologii. Jak to więc możliwe, że błyskawicznie przetwarza miliony wierszy danych? Sekret tkwi w architekturze. Najważniejsze biblioteki analityczne, takie jak NumPy czy Pandas, pod maską wykorzystują niezwykle szybkie, niskopoziomowe języki programowania (głównie C, a nawet Fortran). Używając Pythona, korzystamy po prostu z bardzo czytelnego, wygodnego „pilota”, którym wydajemy polecenia zoptymalizowanym, potężnym silnikom obliczeniowym.
Python często bywa określany w środowisku IT jako język stosunkowo wolny w porównaniu do innych technologii. Jak to więc możliwe, że błyskawicznie przetwarza miliony wierszy danych? Sekret tkwi w architekturze. Najważniejsze biblioteki analityczne, takie jak NumPy czy Pandas, pod maską wykorzystują niezwykle szybkie, niskopoziomowe języki programowania (głównie C, a nawet Fortran). Używając Pythona, korzystamy po prostu z bardzo czytelnego, wygodnego „pilota”, którym wydajemy polecenia zoptymalizowanym, potężnym silnikom obliczeniowym.
Mając zainstalowane i opanowane te cztery biblioteki, jesteśmy od strony technicznej w pełni gotowi do pracy. Taka konfiguracja środowiska to wszystko, czego potrzebujemy na start, by rozwiązać zdecydowaną większość analitycznych problemów, z jakimi spotkamy się w codziennej pracy biznesowej.
Jak efektywnie się uczyć?
Kiedy mamy już przygotowane środowisko, łatwo wpaść w tzw. „tutorial hell”, czyli pułapkę nieskończonego oglądania poradników. Gdy mechanicznie przepisujemy kod za instruktorem, zyskujemy jedynie złudne poczucie postępu. Takie podejście nie uczy nas samodzielnego rozwiązywania problemów, przez co w zderzeniu z nowym, nieschematycznym zadaniem biznesowym często nie potrafimy napisać ani jednej użytecznej linijki kodu.
Aby nasza nauka przynosiła realne efekty, musimy szybko przejść od teorii do praktyki. Zamiast odtwarzać sztuczne scenariusze z kursów, najlepiej zacząć budować własne, mniejsze projekty, bo to właśnie one nauczą nas najwięcej w najkrótszym czasie. Analiza naszych domowych finansów, zestawienie statystyk ulubionej drużyny sportowej czy zbadanie lokalnych cen nieruchomości to zadania, które wymuszą na nas samodzielne poszukiwanie rozwiązań.

Takie podejście sprawdza się najlepiej, ponieważ praca z prawdziwymi, często nieuporządkowanymi zbiorami informacji zmusza nas do napisania autentycznego, działającego kodu, który będzie różnić się w zależności od zadania. Kiedy sami musimy wymyślić, jak przefiltrować konkretną tabelę, wyciągnąć kluczowe statystyki z arkusza czy połączyć ze sobą dwa różne pliki, zaczynamy intuicyjnie rozumieć mechanikę poznanych bibliotek i efektywnie uczymy się analitycznego myślenia.
Ile czasu może zająć nauka?
Zanim przejdziemy do konkretnych szacunków, musimy zaznaczyć jedną kluczową kwestię: czas nauki to sprawa wysoce indywidualna. Zależy on od naszej systematyczności, motywacji oraz tego, ile godzin w tygodniu jesteśmy w stanie na nią poświęcić. Zamiast operować na ogólnikach, najlepiej oszacować ten proces na podstawie bardzo typowego zadania analitycznego, które dobrze obrazuje realny nakład pracy potrzebny do automatyzacji naszych codziennych obowiązków.
Mamy folder, w którym znajduje się dwanaście oddzielnych plików CSV – po jednym na każdy miesiąc sprzedaży. Naszym celem jest napisanie jednego programu, który samodzielnie je połączy, oczyści z błędów, wykona obliczenia statystyczne i wygeneruje profesjonalne wykresy zapisane bezpośrednio do pliku PDF.
Dane w każdym z plików prezentują się w taki sposób:

Skrypt realizujący zadanie:

Efektem końcowym jest czysty raport zawierający wykres w formacie PDF, który generuje się w ułamku sekundy po każdym uruchomieniu skryptu:

Patrząc na kod z naszego przykładu i zakładając brak wcześniejszego doświadczenia technicznego, musimy oddzielić opanowanie samych narzędzi od swobodnego, bezbłędnego programowania.
Opanowanie podstaw i narzędzi (Pierwsze 2-3 miesiące)
Optymalny podział czasu dla osoby zaczynającej od zera wyglądałby następująco:
- Logika języka i fundamenty (ok. 3–4 tygodnie): To kluczowy etap, w którym przestawiamy się na myślenie programistyczne. Zrozumienie, jak działają zmienne , instrukcje warunkowe i pętle , wymaga czasu na spokojne utrwalenie, by w przyszłości pracować samodzielnie.
- Zarządzanie plikami z biblioteką os (ok. 1 tydzień): Stosunkowo krótki etap nauki „rozglądania się” programu po folderach i automatycznego pobierania list plików.
- Przetwarzanie danych w Pandas (ok. 4–6 tygodni): To absolutne serce analityki w Pythonie. Wymaga najwięcej praktyki, aby płynnie wczytywać pliki, radzić sobie z brakującymi wartościami i łączyć wiele źródeł w jeden spójny zestaw.
- Wizualizacja wyników (ok. 1–2 tygodnie): Opanowanie elastycznej biblioteki Matplotlib i estetycznej nakładki Seaborn , aby zamieniać suche liczby w profesjonalne wykresy, gotowe np. do wklejenia w prezentację.
💡 Ciekawostka: Czy NumPy jest nam jeszcze potrzebne?
Choć wcześniej omawialiśmy potęgę biblioteki NumPy jako matematycznego fundamentu, w naszym docelowym skrypcie nie ma po niej śladu. Dlaczego? Nowoczesne wersje biblioteki Pandas są na tyle zaawansowane i zoptymalizowane, że przy standardowych zadaniach analitycznych nie wymagają już od nas bezpośredniego importowania i odwoływania się do NumPy. Zamiast tego wpisujemy polecenia jako zwykły tekst (np. 'sum’, 'mean’). NumPy nadal pracuje „pod maską” i dba o niezwykłą wydajność tych obliczeń, ale z punktu widzenia użytkownika nasz kod pozostaje znacznie czystszy i łatwiejszy do napisania.
Choć wcześniej omawialiśmy potęgę biblioteki NumPy jako matematycznego fundamentu, w naszym docelowym skrypcie nie ma po niej śladu. Dlaczego? Nowoczesne wersje biblioteki Pandas są na tyle zaawansowane i zoptymalizowane, że przy standardowych zadaniach analitycznych nie wymagają już od nas bezpośredniego importowania i odwoływania się do NumPy. Zamiast tego wpisujemy polecenia jako zwykły tekst (np. 'sum’, 'mean’). NumPy nadal pracuje „pod maską” i dba o niezwykłą wydajność tych obliczeń, ale z punktu widzenia użytkownika nasz kod pozostaje znacznie czystszy i łatwiejszy do napisania.
Przejście do płynności analitycznej
Po pierwszym kwartale będziemy już w stanie samodzielnie zautomatyzować raportowanie, choć będziemy jeszcze często wspierać się dokumentacją lub wyszukiwarką. Jednak prawdziwa swoboda przychodzi z praktyką i mądrym wykorzystaniem nowoczesnych narzędzi:
- Wsparcie AI: Pokaż mu błąd, a nie każ mu pisać wszystkiego
W dzisiejszym świecie, nauka i praca z Pythonem są nierozerwalnie związane z narzędziami AI (np. ChatGPT, Copilot, Gemini). Kod pisze się „sam” szybciej niż kiedykolwiek. Czy to dobrze? Bez solidnych fundamentów logicznych, AI może generować kod, który działa „przypadkowo”, lub co gorsza, kod nieoptymalny i trudny do debugowania (szukania błędów). - Kluczem jest prompting, czyli umiejętność zadawania pytań.
W pierwszych miesiącach, AI powinno być Twoim konsultantem, a nie programistą.
Zamiast mówić: „Napisz mi skrypt do łączenia tabel w Pandas.” powiedz: „Próbuję połączyć dwie tabele, klienci i faktury, na podstawie kolumny NIP. Tabela faktury ma 10,000 wierszy, a klienci ma 200. Jaka jest różnica między merge z how=’left’ a how=’inner’ dla moich danych, i na co powinienem uważać?” - Używaj AI do debugowania: Kiedy otrzymasz błąd, nie ignoruj go. Skopiuj cały komunikat błędu i zapytaj AI: „Co oznacza ten komunikat błędu w kontekście mojego kodu? Pokaż mi przykładową sytuację, która mogłaby go wywołać, i jak ją naprawić”. To przyspiesza naukę, pokazując przyczyny i skutki.
- Rola w optymalizacji (po 3 miesiącach): Kiedy rozumiesz już fundamenty, AI staje się potężnym narzędziem do optymalizacji: „Mam ten działający kod do przetwarzania plików. Zaproponuj sposób na uczynienie go bardziej czytelnym i szybszym, bez zmiany jego funkcjonalności”.
Wracając do szacowania czasu w opisywanym przykładzie:
- Miesiące 3-6: Na tym etapie przestajemy reagować stresowo na błędy w konsoli. Zaczynamy rozumieć, jak uodparniać nasze skrypty na sytuacje, w których Excel dostarcza nam błędne dane. Co jednak najważniejsze, zaczynamy pisać kod, który jest nie tylko skuteczny, ale przede wszystkim czystszy i lepiej ustrukturyzowany.
- Po 6 miesiącach: Dopiero po około pół roku pracy na realnych, nieschematycznych zadaniach biznesowych zaczynamy pisać kod płynnie. To moment, w którym potrafimy samodzielnie przełożyć problem analityczny na gotowy, optymalny algorytm bez ciągłego zaglądania do dokumentacji.
Pamiętaj, że powyższe ramy czasowe to tylko drogowskaz, a nie wyścig z czasem. Każdy z nas przyswaja nową wiedzę we własnym tempie. Najważniejsza nie jest szybkość zaliczania kolejnych etapów, ale systematyczność i dogłębne zrozumienie materiału.
Podsumowanie
Przejście ze standardowych arkuszy kalkulacyjnych na środowisko programistyczne to inwestycja, która fundamentalnie zmienia sposób pracy z danymi. Jak pokazuje nasz przykład, zyski w postaci zaoszczędzonego czasu są ogromne, jednak proces opanowania tych narzędzi wymaga od nas cierpliwości i odpowiedniego planu.
Aby uniknąć frustracji na starcie, zakładając regularną naukę (np. około godziny dziennie), musimy racjonalnie rozdzielić nasze oczekiwania:
- Perspektywa około kwartału: To czas potrzebny na stworzenie pierwszego, działającego narzędzia ułatwiającego nam pracę. Na tym etapie automatyzujemy powtarzalne raporty, choć możliwe, że wciąż będziemy wspierać się dokumentacją.
Perspektywa około pół roku: To moment osiągnięcia analitycznej swobody. Zaczynamy płynnie rozwiązywać nieschematyczne problemy i pisać optymalny kod bez ciągłego zaglądania do poradników.

Warto pamiętać, że programowanie w obszarze analizy danych to proces niezwykle logiczny. Nie polega na uczeniu się regułek na pamięć, ale na umiejętnym rozwiązywaniu problemów. Z każdym kolejnym przeanalizowanym przypadkiem i nowym napisanym skryptem, przyswajanie nowej składni będzie stawało się coraz szybsze i bardziej intuicyjne.
Bariera wejścia, która na początku może wydawać się trudna do pokonania, bardzo szybko znika. W jej miejsce pojawia się satysfakcja z odzyskanego czasu, którego już nigdy nie będziemy musieli marnować na czasochłonne, ręczne formatowanie tabel w arkuszach kalkulacyjnych.




