


Pułapki modelowania danych w Power BI - praktyczne wskazówki dla lepszych raportów
DAX
Power BI
Jednym z najczęściej zadawanych pytań na szkoleniach traktujących o bazach danych czy narzędziach Business Intelligence, jest co to jest model danych. Odpowiedź wydaje się banalna bo w takim ogólnym pojęciu podchodząc książkowo do tego tematu można by powiedzieć, że jest zbiór tabel połączonych relacjami. I zazwyczaj na takim poziomie zrozumienia początkowi użytkownicy narzędzi Business Intelligence takich jak Power BI czy Power Pivot znają temat modelowania danych.
Ale drążąc dalej ten temat należy się zastanowić, w jakim celu w ogóle jest mi potrzebny model danych? Dlaczego miałbym sobie utrudnić życie projektując tabele faktów i wymiarów, tworząc klucze własne i obce w tabelach? Czym są tabele rozszerzone w Power BI? Czy pojęcia o wdzięcznych nazwach kardynalność i kierunek filtrów krzyżowych są aż tak ważne, żeby zajmować sobie nimi głowę zamiast zacząć od razu tworzyć piękne kolorowe wykresy w Power BI Desktop? Tego typu pytania warto sobie postawić i zastanowić się nad nimi ponieważ aspekty te mają kluczowy wpływ na dalsze analizy w naszym raporcie.
Błędy popełnione na początku nieważne czy na etapie przygotowania danych w Power Query czy na etapie modelowania będą coraz bardziej bolesne na kolejnych etapach gdy nasze wyliczenia nie będą zgodne z oczekiwaniami, lub nie będą w ogóle możliwe do wykonania. Zdecydowanie warto poświęcić kilka chwil na odpowiednie przygotowanie modelu aby uniknąć problemów wydajnościowych, problemów z relacjami czy odwołań cyklicznych w miarach używając DAX. Proces ten powinien być wykonany w sposób świadomy bo podobnie jak w wielu innych sprawach gdy na początku zaoszczędzimy kilka minut to później stracimy kilka godzin na odnalezienie błędów i powodów nieprawidłowości.
Spróbujmy zatem zastanowić się od samego początku, jakie pułapki nas czekają podczas modelowania danych aby nigdy ich nie popełnić.
Jeżeli model danych to zbiór tabel a zbiór to więcej niż jeden, to znaczy, że potrzebujemy przynajmniej dwóch tabel aby zrobić model i w logiczny sposób po kluczu je połączyć. I tutaj już powinna nam się zapalić lampa z tyłu głowy, że nie tworzymy jednej wielkiej tabeli z wieloma kolumnami jak np. w MS Excel aby wykonać analizy. To jest właśnie to czego chcemy uniknąć w modelowaniu czyli powtarzania tych samych rekordów w każdym wierszu. Jest to bardzo kosztowne dla programu ponieważ jest on zmuszony do skompresowania ogromnej ilości danych a przy analizach do przeskanowania wiele razy tych samych rekordów w wierszach.
Poniżej przykład takiej tabeli, gdzie wiele razy zostały powtórzone nazwy krajów, kontynentów, kategorii itp. I to jest pierwszy element, z którego Power BI byłby niespecjalnie zadowolony.
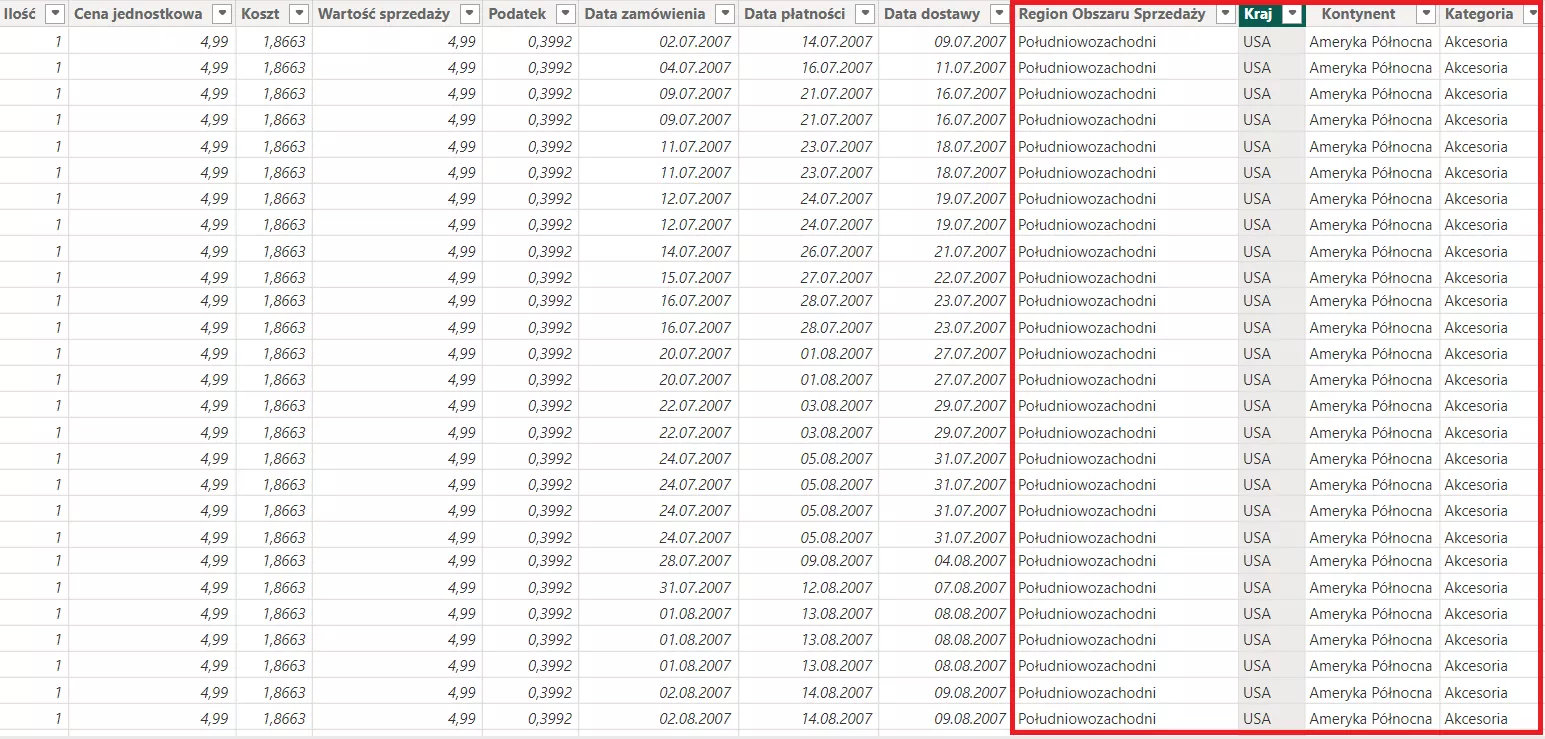
Zdecydowanie lepiej utworzyć dwa typy tabel.
Faktów – która przechowa nam dane typu ILE i KIEDY oraz
Wymiarów – która opisze nam atrybuty CO,KTO,GDZIE.
Łatwo się zorientować, że gdy zastosujemy takie tabele to bez większego problemu połączymy je po kluczach (które z punktu wydajnościowego warto żeby były liczbowe) i pobierzemy z nich dane bez powtarzania rekordów. Kolumny z danymi opisującymi regiony sprzedaży czy kategorie nadal są dla nas dostępne ale skorzystamy z relacji a więc nie potrzebujemy dokładać kosztowych kolumn do tabel faktów.
Poniżej przykład tych samych danych w modelu.
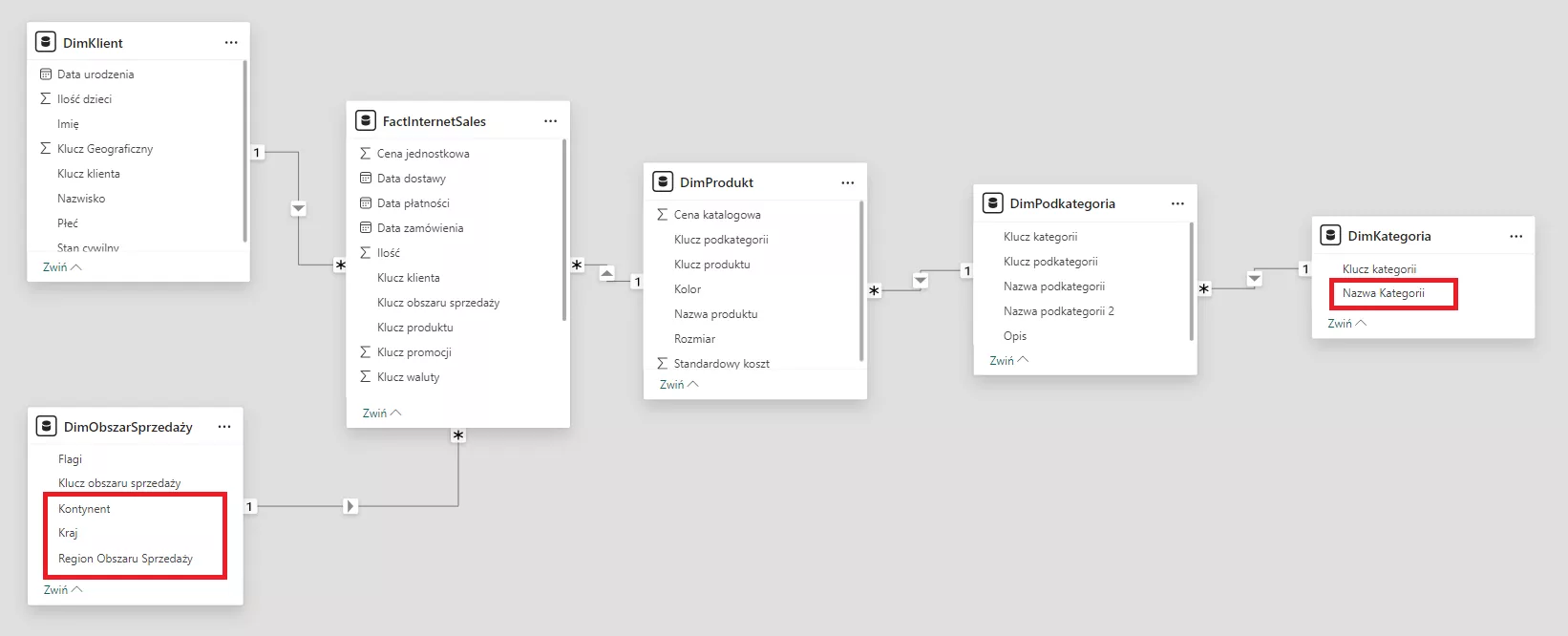
Można zauważyć na powyższym obrazie, że tabele połączone są strzałkami czyli relacjami – w fachowym żargonie zwanymi kardynalnością oraz są tam małe jednostronne strzałeczki odpowiadające za kierunek przepływu danych w modelu. Te na początku drobne elementy są szalenie istotne i można tutaj wpaść w kolejne pułapki jeżeli trochę przekombinujemy ale o tym troszeczkę później.
Wracając do myśli poprzedniej z modelem wiemy już, że utworzenie modelu danych jest bardzo dobrym pomysłem. Zapoznajmy się jeszcze z dwoma ważnymi pojęciami modelowania danych. Schemat gwiazdy i płatka śniegu. Jeżeli wyobraziliście sobie siebie zjeżdżających ze stoku na nartach o zmroku wśród gwiazd na niebie to znaczy, że czas na ferie i warto zaplanować krótki wyjazd. Niestety w tym artykule nie będzie ani nart, ani śniegu o stokach nie wspominając, więc wróćmy do świata tabel i zastanówmy się co w modelowaniu danych te pojęcia oznaczają.
Schemat gwiazdy to schemat gdzie mamy tabele faktów i wiele wymiarów jak poniżej:
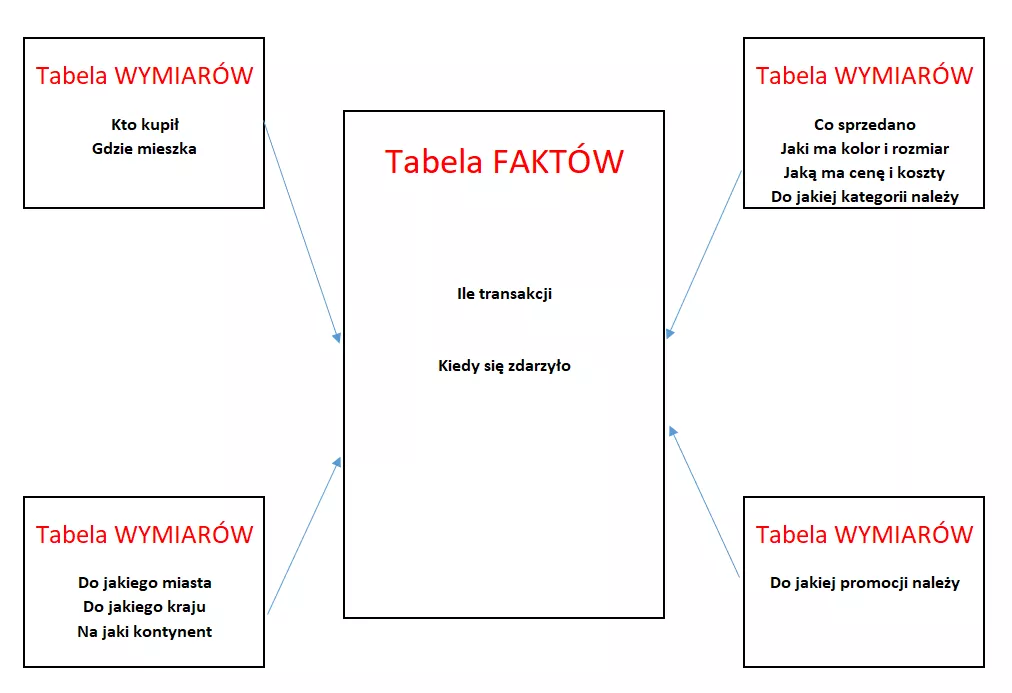
Jak wspomniałem wcześniej fakty nie opisują tylko zliczają i informują nas kiedy coś się stało, natomiast wymiary to proste tabele słownikowe opisujące nasze atrybuty.
Schemat płatka śniegu to schemat gdzie mamy tabele faktów i wiele wymiarów i połączonych do nich podwymiarów:
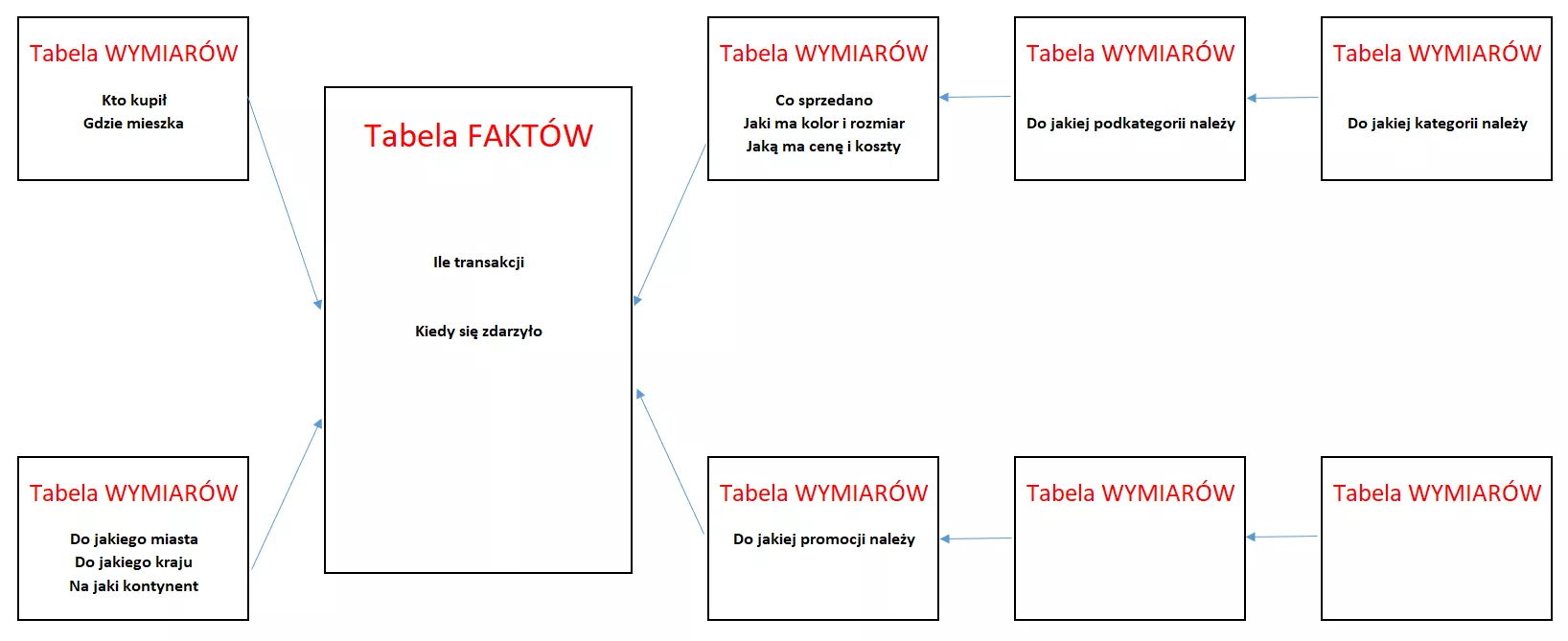
Warto zadać podstawowe pytanie jak jest różnica między nimi?
Błędną odpowiedzią byłoby stwierdzenie, że szczegółowością danych a z moich doświadczeń większość kursantów tak uważa. Szczegółowość jest taka sama ponieważ dane są dokładnie takie same ale w większej ilości tabel. Schematy te różnią się rozproszeniem danych czyli unikamy powtarzania rekordów w wierszach tabeli. Możecie spotkać się także z pojęciem normalizacji danych, czyli właśnie rozłożeniem danych na wiele tabel.
Jednym z moich ulubionych stwierdzeń dotyczących tego tematu jest „Byle jakie słowniki – byle jakie analizy” bo rzeczywiście jeżeli wymiary nie będą szczegółowe to niestety nie będzie z czego tych analiz wykonać. Warto więc poświęcić troszeczkę czasu na początku na przygotowanie tego elementu aby w przyszłości tworzyć zaawansowane i szczegółowe raporty w Power BI.
Wybranie schematu zależy od struktury danych oraz celu ich wykorzystania. Pamiętaj, że są określone sytuacje gdzie potrzebujemy wymusić unikatowość danych. Można zawsze wykorzystać funkcję DAX jak VALUES czy DISTINCT ale to wymaga już pewnej biegłości języka DAX. I tak zupełnie przypadkowo wywołałem do tablicy kolejne ciekawe (jedno z moich ulubionych pytań) czyli jaka jest różnica między tymi funkcjami? W tym artykule pozostawię to jako rąbek tajemnicy – może kiedyś przyjdzie czas na jej wyjaśnienie😊
Warto także mieć świadomość, co tak naprawdę dzieje się w trybach silnika Vertipaq odpowiedzialnego za przetwarzanie obliczeń w Power BI. Wszystkie obliczenia, które są wykonywane nie są wyliczane na tabelach, które my jako użytkownicy widzimy tylko na tabelach rozszerzonych, które są generowane w pamięci. Temat ten także zdecydowanie wykracza poza ramy tego artykułu ale warto znać takie pojęcia nawet na podstawowym poziomie zrozumienia bo ta wiedza może być przydatna przy zrozumieniu pewnych kłopotliwych sytuacji w Power BI. Często pojawiają się pytania dlaczego Power BI nie potrafi dobrze zsumować kilku wartości czy dlaczego dzieli przez niewłaściwe wartości. Wynika to z koncepcji języka DAX, który warto szczegółowo poznać aby nie wpadać w pułapki😊
Gdy wiemy już jak zbudować model danych to spróbujmy zaprzyjaźnić się z tymi strzałeczkami łączącymi tabele.
W Power BI mamy do dyspozycji trzy kardynalności :
1:1
1:*
*:*
Jeżeli nie chcemy narobić sobie problemów starajmy się stosować zawsze kardynalność 1:*
W Power Pivot tylko taka kardynalność jest dostępna.
1 oznacza unikatowość klucza czyli wartość nie może zostać powtórzona i jednoznacznie opisuję co oznacza w tabeli. Nazywa się to kluczem własnym.
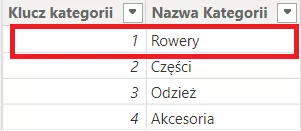
Natomiast * czyli wiele oznacza, że wartości klucza się powtarzają i to jest klucz obcy.
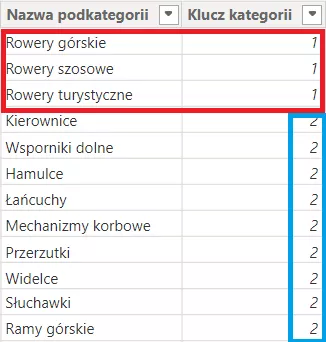
Przykład poniżej obrazuję, że tabele DimKategoria i DimPodkategoria połączone są właśnie taką kardynalnością. Oznacza to, że np. do kategorii Rowery należy wiele podkategorii. Taka sama historia jest z kategorią Części i każdą inną.
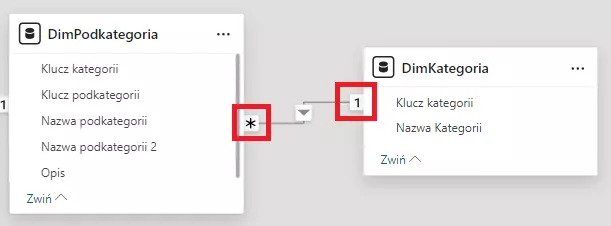
Wynika z tego, że kolejną czyhającą na nas pułapką jest zastosowanie kardynalności 1:1 lub wiele do wiele (*:*). Zawsze dwa razy się zastanówmy dlaczego chcemy to zrobić. Może lepiej utworzyć tzw. tabele pomostową, która połączy te dwie tabele za pomocą 1:*. Przecież zależy nam żeby Power BI był zadowolony i chciał z nami współpracować prawda? Pamiętacie jak na początku wspominałem o zaoszczędzonych kilku minutach i zmarnowanych kilku godzinach. Ten przykład się w to idealnie wpasowuje. Nie utworzymy tabeli to mamy 20 minut na kawę ale kiedyś tego pożałujemy i zmarnujemy pół dnia na odkręcenie tej zawiłości gdy nie będzie można wykonać pewnych obliczeń. Ile wtedy byśmy oddali żeby cofnąć czas i tej kawy nie wypić? Niestety Power BI nie będzie taki wyrozumiały i w ten feralny dzień nie tylko nie wypijemy spokojnie kawy ale nie zjemy nawet obiadu☹

Ostatnim ważnym często niedocenianym elementem jest ta malutka strzałeczka w relacji między tabelami. Jest to filtr krzyżowy a używając nomenklatury kierunek propagacji filtru w modelu. Tłumacząc to na prosty język dane przepływają zawsze (domyślnie) od strony jeden do wiele lub jak kto woli od wymiarów do faktów.
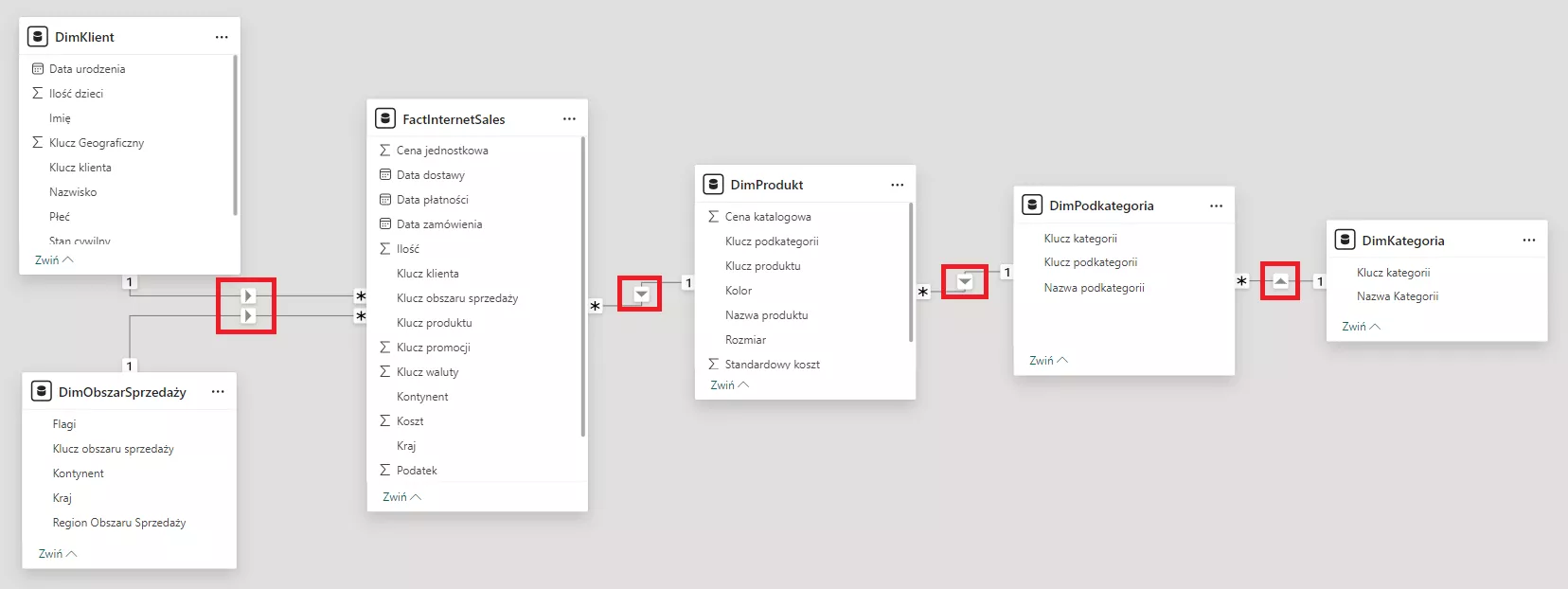
Aby uniknąć kolejnej pułapki starajmy się zachować właśnie jednokierunkowy filtr. Oznacza to, że będzie można wyliczyć dane z dowolnego wymiaru i tabeli faktów na wizualizacjach.
A co jeżeli potrzebujemy wiedzieć ilu klientów kupiło nasze produkty czyli wykonać obliczenie gdzie musimy przejść przez fakty do innego wymiaru? Przecież filtr nie przejdzie od wiele do jeden.
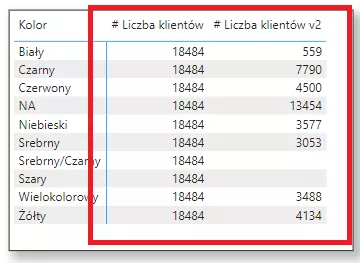
Poniżej obraz prezentujący pewien problem. Na wierszach macierzy wykorzystam kolumnę z kolorem produktu z tabeli DimProdukt, natomiast na wartości zliczę liczbę klientów w bazie (użyje do tego funkcji COUNTROWS())
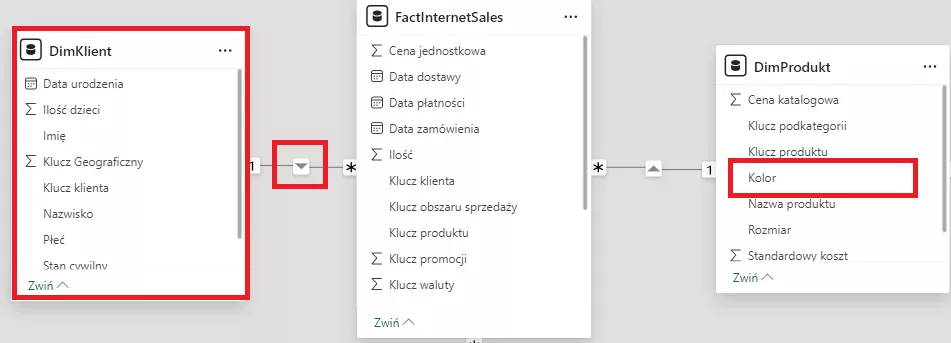
Moje obliczenie niestety nie będzie poprawne bo nie jest możliwe przejście od strony wiele do jeden.
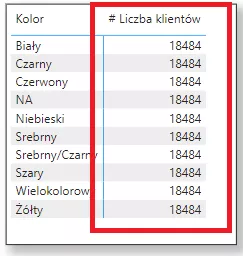
Upraszczając sobie raportowe życie na początku mógłbym utworzyć kierunek dwustronny – ale nie byłoby to dobrym pomysłem z wielu względów. Można by znowu powiedzieć UWAGA! Pułapka – narobisz sobie problemów z wydajnością i częścią obliczeń w modelu.
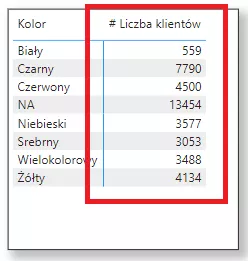
Na potrzeby tego przykładu utworzę kierunek dwustronny. Proszę zwrócić uwagę, że pozwoliło mi to uzyskać informację ilu klientów kupiło produkty w konkretnych kolorach a to oznacza, że osiągnąłem swój cel – niestety kosztem wydajności oraz innych problemów związanych z relacjami w modelu.
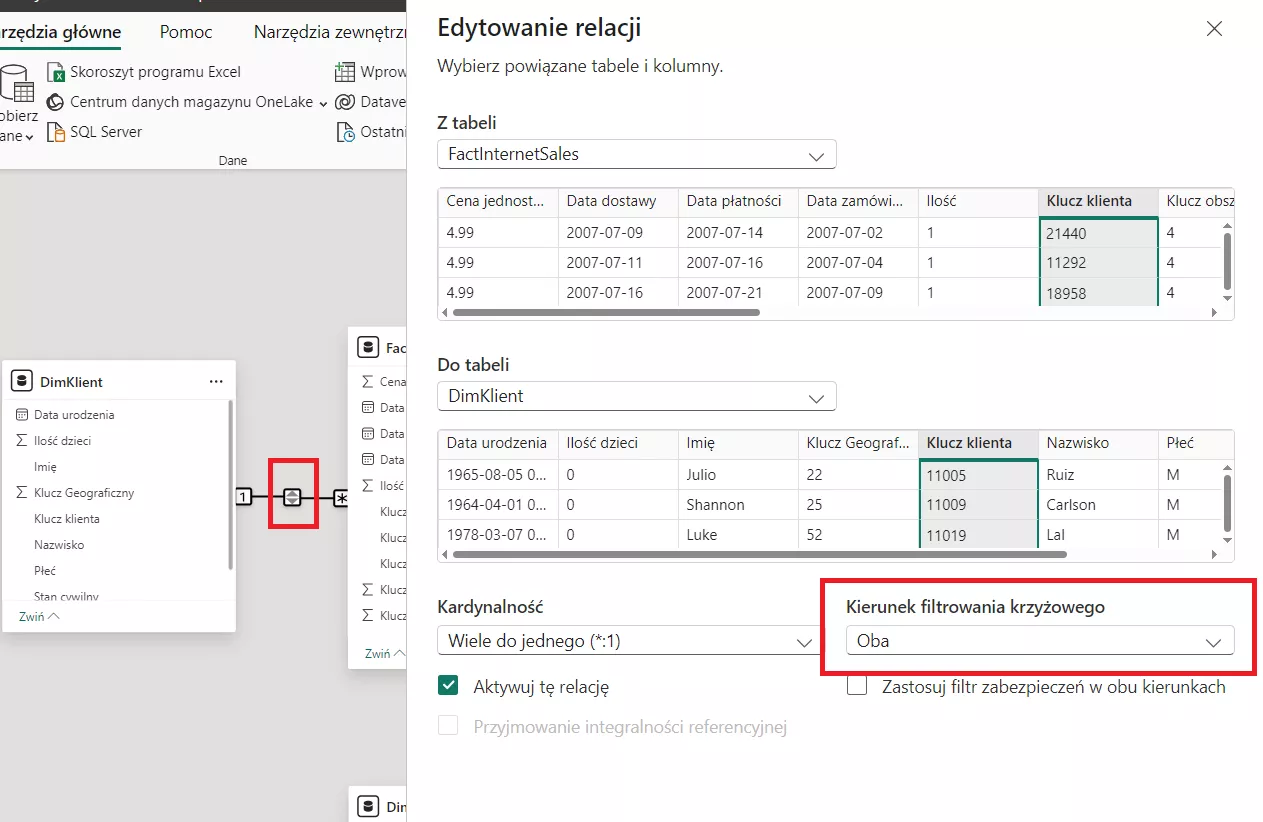
Zdecydowanie tego nie chcemy więc użyjemy potęgi języka DAX czyli funkcji Calculate, która może wszystko i jako jej żołnierza powołamy funkcję CROSSFILTER aby udrożnić przejście na potrzeby obliczenia
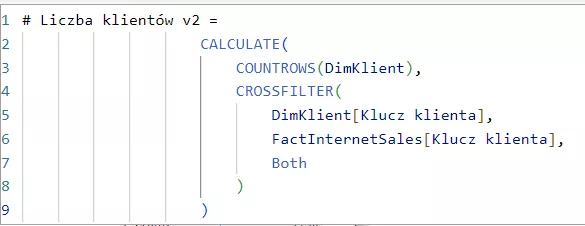
Tak wykonane obliczenie za pomocą miary pozwoli uzyskać pożądany efekt i nie ma mowy o jakichkolwiek problemach związanych z relacjami ponieważ DAX tylko na potrzeby tej miary pozwoli wykonać taki filtr. Od czego mamy Calculate – oczywiście, że od zadań specjalnych😊
Więcej o funkcji Calculate przeczytasz w poniższym artykule
Przechodząc powoli do podsumowania tych zawiłości modelowania danych zdecydowanie nie warto przekombinować na siłę pewnych rozwiązań jeżeli nie są one konieczne bo wpadniemy w wiele pułapek, których przecież chcemy uniknąć.
Na koniec wypunktujmy dobre rady aby jak mantry się ich trzymać podczas tworzenia modelu danych. Później Power BI odwdzięczy nam się wzorowa współpracą i pięknymi dashboardami wprowadzając nasze dane na kolejny poziom zrozumienia.
- Korzystaj ze schematu gwiazdy lub płatka śniegu zamiast struktur płaskich
- Upewnij się, że klucze są unikatowe w tabelach wymiarów
- Używaj odpowiednich typów danych
- Twórz poprawne relacje między tabelami
- Unikaj relacji dwukierunkowych
- Minimalizuj rozmiar modelu
- Twórz miary zamiast dodawać kolumny obliczeniowe, gdy to możliwe
- Twórz zmienne w DAX, aby poprawić czytelność i wydajność miar
I na koniec złota myśl:
Dobrze zaprojektowany model danych w Power BI jest podstawą efektywnego raportowania. Unikanie tych błędów pomoże w osiągnięciu lepszej wydajności i dokładności analiz.
Powodzenia😊




