
Wczytywanie plików z PDF do Excela
Excel
Spis treści:
Wstęp
W codziennej pracy z analizą danych coraz częściej mamy styczność z plikami dostarczanymi w formacie PDF. W wielu przypadkach konieczne jest ich zaimportowanie do Excela i odpowiednie przygotowanie, aby mogły być efektywnie wykorzystywane w dalszych analizach lub raportach.
Bardzo często zdarza się, że otrzymujemy kolejne pliki o bardzo podobnej strukturze, których import i przygotowanie powinno być wykonane w ten sam sposób, jak dla wcześniejszych danych. Ręczne powtarzanie wszystkich czynności dla każdego pliku osobno byłoby czasochłonne i zwiększałoby ryzyko popełniania błędów. Dlatego zamiast powtarzać te same operacje wielokrotnie, możemy przygotować automatyczny mechanizm importu i transformacji danych w edytorze Power Query w Excelu. W tym artykule przedstawimy, jak krok po kroku zbudować taki mechanizm na przykładzie wielostronicowych plików PDF z danymi sprzedażowymi, tak, aby kolejne pliki, które dodamy do źródła, mogły być importowane i przetwarzane spójnie i w pełni automatycznie.
Przykład
Otrzymaliśmy dane dotyczące sprzedaży trzech produktów. Transakcje sprzedażowe zostały zarejestrowane we wrześniu 2025 i pochodzą z wielu województw:
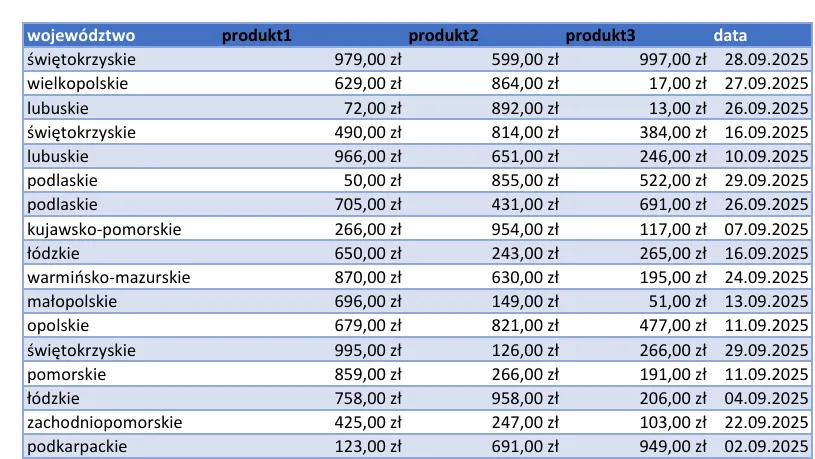
Całość zapisana jest w wielostronicowym (20 stron) pliku PDF.
Wiemy, że rozliczenie kolejnych miesięcy (październik, listopad i grudzień) będzie przygotowane w podobnym formacie – również w plikach PDF, których dane będą miały podobny układ.
Naszym celem jest przygotowanie zautomatyzowanego raportu, w którym rozliczymy transakcje dotyczące trzech produktów z dostarczonych plików sprzedażowych. Wykorzystamy do tego narzędzie Power Query, które pozwoli nam zaimportować i przygotować dane z pliku do dalszej analizy oraz zapisać wykonywane kroki, które będą się wykonywać dla każdego kolejnego pliku, który otrzymamy.
Jak zaimportować pliki
Przechodzimy do zakładki dane i rozwijamy opcję Pobierz dane. Zauważ, że dane z plików PDF możemy importować na dwa sposoby – wybierając opcję Z pliku PDF lub Z folderu:
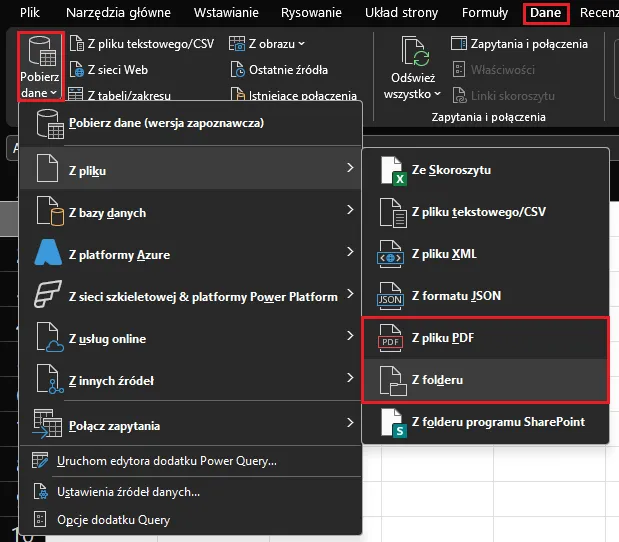
W naszym przypadku skorzystanie z opcji importu z folderu będzie korzystniejsze i zaoszczędzimy sporo czasu – możemy utworzyć folder do którego będą kolejno dodawane nowe pliki PDF. Power Query będzie odczytywać wszystkie pliki z folderu po kolei, przez co kroki transformacyjne, które wykonamy, zostaną automatycznie zastosowane dla każdego pliku – nawet jeśli zostanie dodany do folderu w późniejszym czasie. Dzięki temu cały proces stanie się w pełni zautomatyzowany.
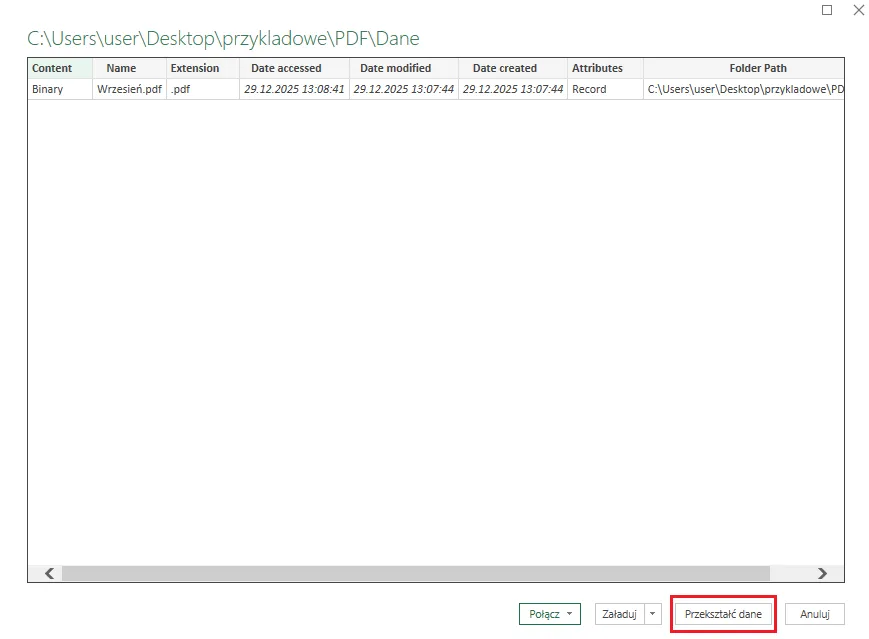
Wybieramy Z folderu, a następnie Przekształć dane, by przejść do edytora Power Query:
Następnie klikamy ikonę dwukrotnej strzałki przy kolumnie Content:
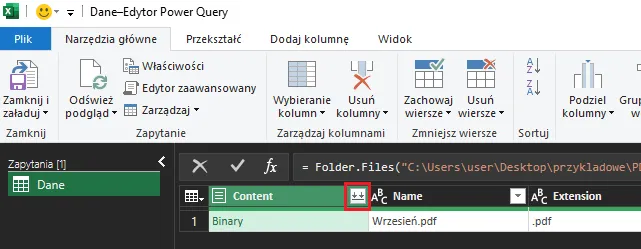
Kolejną czynnością będzie wskazanie, które elementy pliku PDF mają zostać rozkodowane przez Power Query.
Jak Power Query rozkodowuje pliki PDF
Power Query podczas importu pliku PDF najpierw analizuje jego zawartość i rozdziela ją na strony, a następnie stara się rozpoznać w każdej stronie struktury tabelaryczne. Dzięki temu możemy wybierać zarówno całe strony, jak i wyodrębnione tabele, a PQ automatycznie konwertuje dane do formatu, który można przekształcać i analizować w Excelu.
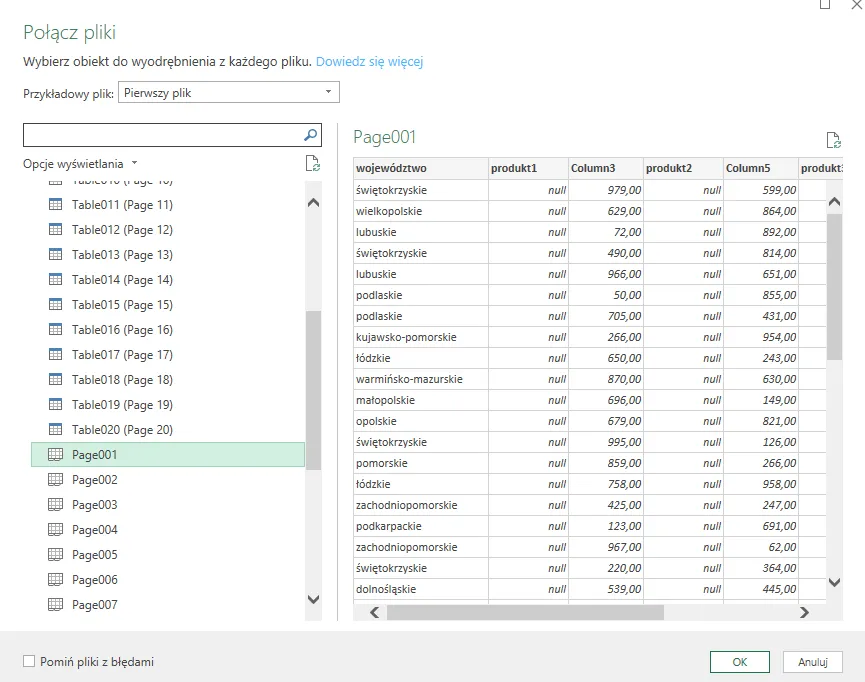
Nie ma jednak dużego znaczenia, czy pobierzemy dane z całych stron czy z tabel w pliku – różnica byłaby widoczna tylko jeśli na stronach pliku PDF byłyby również dodatkowe treści niebędące tabelami. W takim przypadku wygodniej jest korzystać z opcji tabel, ponieważ Power Query automatycznie rozpoznaje struktury tabelaryczne, co ułatwia dalszą analizę.
Przy imporcie wybór konkretnych tabel (lub stron) w przypadku pojedynczego pliku miałby sens, lecz nie wiemy ile tabel (stron) będzie dostarczone w plikach kolejnych. Ponieważ chcemy przygotować mechanizm importu w pełni automatyczny, wygodniej będzie „wyjść” z kontekstu pełnego pliku PDF. Przy imporcie za pełny plik odpowiada żółty folder opisany jako Parametr1.
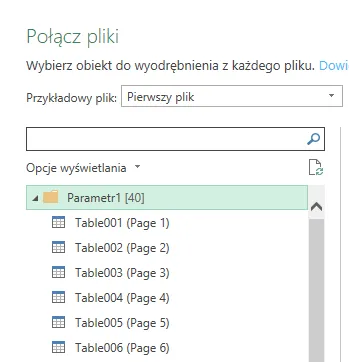
Potwierdzamy zaznaczając OK:
💡 Ciekawostka:
Nazwa Parametr1 przy wyborze źródła może być myląca, ale wynika ona ze specyfiki działania PQ podczas importu danych z folderu. Power Query automatycznie tworzy dodatkowe elementy, które są niezbędne do działania mechanizmu importu plików. Są to m.in. pomocnicze zapytania oraz funkcje, do których przekazywany jest parametr wejściowy w postaci konkretnego pliku (a docelowo konkretnych plików) – stąd nazwa Parametr1 przy wyborze źródła. Dzięki temu każdy kolejny plik przetwarzany jest w identyczny sposób.
Nazwa Parametr1 przy wyborze źródła może być myląca, ale wynika ona ze specyfiki działania PQ podczas importu danych z folderu. Power Query automatycznie tworzy dodatkowe elementy, które są niezbędne do działania mechanizmu importu plików. Są to m.in. pomocnicze zapytania oraz funkcje, do których przekazywany jest parametr wejściowy w postaci konkretnego pliku (a docelowo konkretnych plików) – stąd nazwa Parametr1 przy wyborze źródła. Dzięki temu każdy kolejny plik przetwarzany jest w identyczny sposób.
Przygotowanie danych do analizy
Krokiem pierwszym będzie nałożenie filtru na kolumnę Kind, w której to widać typy zaimportowanych struktur danych – Table, Page. Interesują nas jedynie tabele. Odznaczamy Page i potwierdzamy klikając OK:
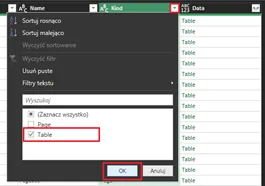
Po nałożeniu filtru:
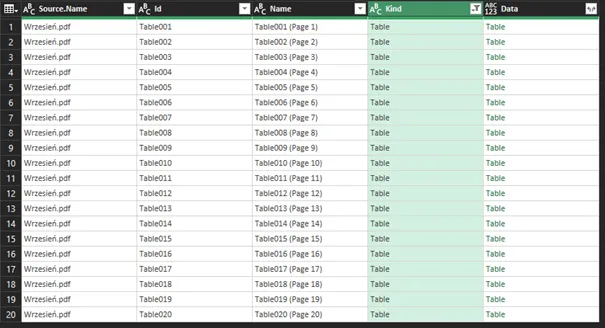
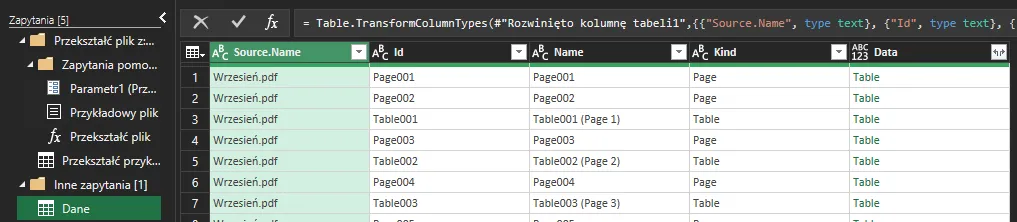
Z punktu widzenia dalszych działań interesują nas tylko kolumny Source.name i Data. Klikając prawym przyciskiem myszy usuwamy zbędne kolumny – Kind, Name i Id:
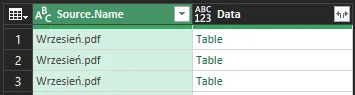
Zwróćmy uwagę na to, że jeden z przycisków do filtrowania wygląda inaczej – znajduje się on w kolumnie Data. Kolumna ta zawiera interesujące nas dane w każdej z zaimportowanych tabel z pliku PDF. Klikamy przycisk i potwierdzamy podpowiedź co do rozpoznanych kolumn, wybierając OK:
„Rozkodowane” dane wyglądają następująco:

Przyglądając się nazwom pobranych kolumn, możemy zauważyć, że same nazwy niepoprawnie opisują zawartość kolumn z danymi, natomiast pierwszy wiersz w tabeli zawiera rzeczywiste nagłówki. Na szczęście przygotowanie właściwych nagłówków w Power Query jest bardzo proste – wystarczy skorzystać z polecenia Użyj pierwszego wiersza jako nagłówków:

Po tym kroku PQ uruchamia automatyczne profilowanie typu danych w poszczególnych kolumnach:

Gdybyśmy jednakże uznali, że typ danych jest niewłaściwie przypisany, należałoby dokonać ręcznej korekty, klikając odpowiednią ikonę w nagłówkach kolumn.
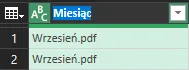
Pierwsza kolumna wymaga ręcznej korekty nazwy. Klikamy dwukrotnie na nagłówku i zmieniamy nazwę kolumny Source.name np. na Miesiąc:
Następnie chcemy oczyścić nazwy miesięcy z końcówki .pdf. Klikamy prawym przyciskiem myszy na nagłówku i wywołujemy menu kontekstowe, z którego wybierzemy polecenie Zamień wartości:
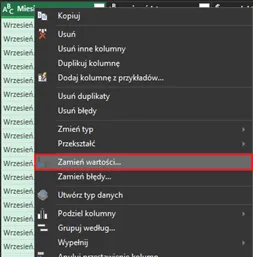
Następnie w polu Wartość do znalezienia wpisujemy .pdf, a pole Zamień na zostawiamy puste:

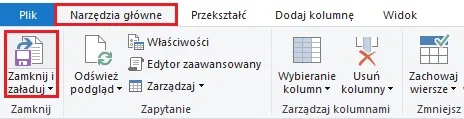
Dane są już poprawnie przygotowane, pozostaje nam „zrzucić” je do arkusza Excel. Aby to zrobić, wybieramy polecenie Zamknij i załaduj w zakładce Narzędzia główne:
Budowa prostego raportu
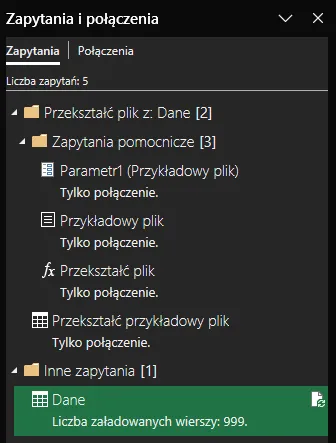
W Excelu w nowym arkuszu w tabeli pojawiły się wszystkie dane, gdzie panel zapytań i połączeń podpowiada nam, że liczba zaimportowanych wierszy wynosi 999:
Na podstawie przygotowanych danych zbudujemy prosty raport, wykorzystując tabelę przestawną. Dzięki temu w łatwy sposób będziemy mogli analizować sprzedaż produktów. Klikamy na dowolne pole wewnątrz tabeli i tworzymy tabelę przestawną:
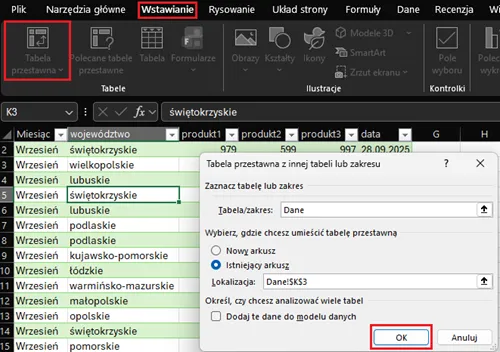
Następnie wybieramy odpowiednie pola:
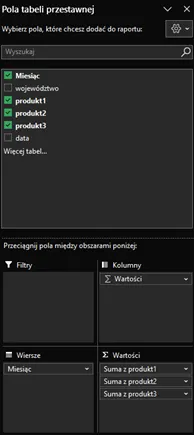
Nasz raport jest już gotowy – import z pliku PDF został wykonany poprawnie!

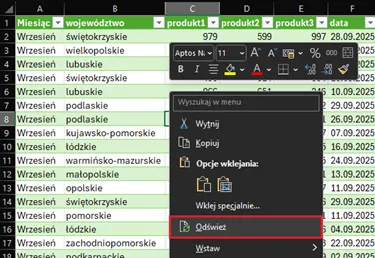
Sprawdzimy teraz, czy nasze rozwiązanie jest dynamiczne. Otrzymaliśmy plik z transakcjami z października. Plik wgrywamy do folderu, z którego importujemy dane, następnie odświeżamy zawartość tabeli:
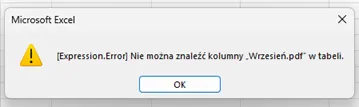
Pojawił się niewiele mówiący komunikat z błędem „[Expression.Error] Nie można znaleźć kolumny „Wrzesień.pdf” w tabeli.”.
Korekty w celu zlikwidowania błędów
Musimy dokonać korekty mechanizmu importu danych, wracając do edytora Power Query. Klikamy dwukrotnie na zapytaniu Dane w zakładce Zapytania i połączenia:
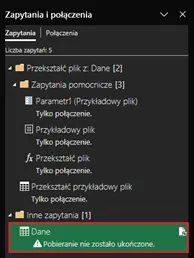
W Power Query, komunikat o błędzie staje się widoczny dopiero po odświeżeniu danych:
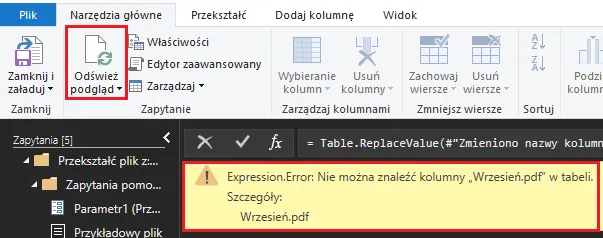
Aby zlokalizować „miejsce” powstania błędu, będziemy od ostatniego kroku cofali się, aż do kroku, w którym błąd nie będzie występował. Krok, w którym błąd nie występuję to:
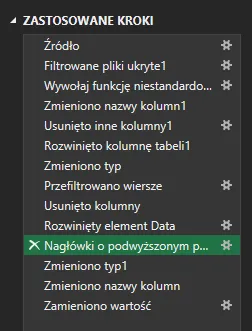
Tego kroku nie korygujemy – korekty będzie wymagał krok kolejny, w którym błąd się pojawił (czyli krok Zmieniono typ1).
💡 Ciekawostka:
Power Query importuje pliki z folderu w kolejności alfabetycznej. Oznacza to, że jeśli w folderze znajdują się pliki zaczynające się od różnych liter (np. „Październik.pdf” i „Wrzesień.pdf”), PQ najpierw przetworzy plik alfabetycznie pierwszy – w tym przypadku „Październik.pdf”.
W naszym wcześniejszym procesie transformacji wszystkie operacje przetwarzały plik „Wrzesień.pdf”, więc ustawione kroki (np. przypisanie typów danych) były dopasowane do kolumn o nazwach pochodzących z tego pliku. Gdy teraz Power Query zaczyna od pliku „Październik.pdf”, kolumny mają inne nazwy, co powoduje pojawienie się komunikatu błędu i konieczność wprowadzenia korekt.
Power Query importuje pliki z folderu w kolejności alfabetycznej. Oznacza to, że jeśli w folderze znajdują się pliki zaczynające się od różnych liter (np. „Październik.pdf” i „Wrzesień.pdf”), PQ najpierw przetworzy plik alfabetycznie pierwszy – w tym przypadku „Październik.pdf”.
W naszym wcześniejszym procesie transformacji wszystkie operacje przetwarzały plik „Wrzesień.pdf”, więc ustawione kroki (np. przypisanie typów danych) były dopasowane do kolumn o nazwach pochodzących z tego pliku. Gdy teraz Power Query zaczyna od pliku „Październik.pdf”, kolumny mają inne nazwy, co powoduje pojawienie się komunikatu błędu i konieczność wprowadzenia korekt.
Zwróćmy uwagę na pasek formuły. Krok Zmieniono typ1 to nic innego jak próba ustawienia właściwych typów danych dla poszczególnych kolumn. Działanie to bazuje na nazwach kolumn, a ponieważ plikiem pierwszym, który Power Query próbuje przetworzyć jest teraz Październik (i tak nazywa się kolumna po kroku Nagłówki o podwyższonym poziomie), to próba ustalenia typu danych dla kolumny pierwszej, która wcześniej nazywała się Wrzesień, kończy się niepowodzeniem.

Mamy dwa sposoby na naprawienie tego błędu. Oba będą bazowały na korekcie formuły:
Usunięcie kolumny pierwszej z profilowania typu danych:

Podejście bardziej profesjonalne – wskazanie kolumny pierwszej nie po nazwie, tylko po indeksie kolumny. Wymagać będzie to dopisania odpowiedniej formuły w języku M:
{ Table.ColumnNames(#”Nagłówki o podwyższonym poziomie”) {0}, type text }

W tym artykule nie będziemy wyjaśniać działania zaproponowanej formuły, zapraszamy do innych artykułów na ten temat lub na szkolenia z języka M.
Jeśli tylko jeden krok odwołuje się do nazwy kolumny, najprostszą poprawką będzie metoda z punktu pierwszego. Ale w naszym mechanizmie importu odwołanie do nazwy występuje również w kroku Zmieniono nazwy kolumn, gdzie również występuje błąd:

Dlatego też, sposób drugi do korekty błędu jest bardziej elastycznym podejściem. Wystarczy, że zastosujemy formułę Table.ColumnNames w kroku Zmieniono nazwy kolumn:
{ Table.ColumnNames(#”Zmieniono typ1”){0}

Problem nazwy kolumny został rozwiązany! Jeśli teraz dołożymy do folderu kolejne pliki z danymi ze sprzedaży z następnych miesięcy, błąd ponownie się nie pojawi.
„Przy okazji” napotkaliśmy kolejny problem widoczny pod nagłówkami kolumn produkt 1,2,3 i data. Objawia się on czerwonym paskiem, który sygnalizuje „złą jakość” danych w kolumnie:
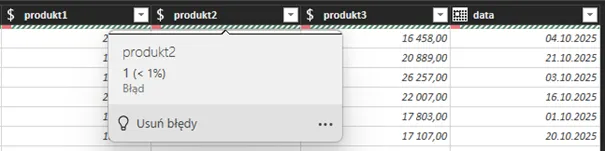
Błąd lokalizujemy tak jak poprzednio – od kroku ostatniego cofamy się do momentu, aż błąd nie będzie widoczny. W naszym przykładzie jest to krok Nagłówki o podwyższonym poziomie.
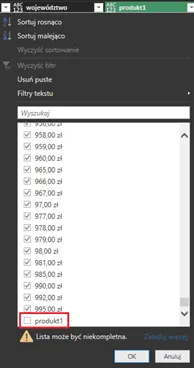
Problem nie występował wcześniej, gdyż pracowaliśmy w kontekście jednego pliku, w którym nagłówki dla danych występowały tylko raz. Przy kilku plikach w folderze, nagłówki powielają się tyle razy, ile plików dodaliśmy do folderu. Zauważ, że w momencie, gdy kończą się dane z pliku Październik i zaczynają się dane z pliku Wrzesień, pojawia się dodatkowy wiersz, który w kroku, ustalającym typ danych liczbowych dla kolumny np. produkt1, powoduje błąd, gdyż dane w kolumnie muszą być jednolite (nie wolno mieszać tekstów z liczbami). Najłatwiej zlokalizować ten błąd, rozwijając filtry dla jednej z problematycznych kolumn (będąc na kroku, w którym błąd jeszcze nie występuje):
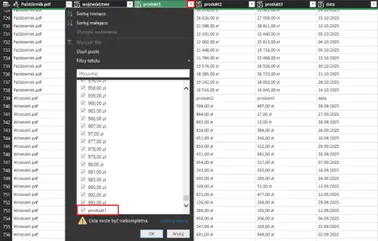
Najprostsza korekta to wyłączenie filtrem niepotrzebnych wierszy nagłówkowych (koniecznie przed krokiem Zmieniono typ1, ale po kroku Nagłówki o podwyższonym poziomie):
Korekty zostały wykonane i nie występują już żadne błędy. Klikamy Zamknij i załaduj i wracamy do arkusza.
Sprawdźmy teraz, czy import danych zostanie wykonany poprawnie dla nowych plików zawierających transakcje z listopada i grudnia. Po dodaniu plików do folderu odświeżamy tabelę i dopiero wtedy odświeżamy raport (tabela przestawna).
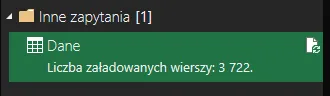
Poprawnie przetworzone 4 pliki dają w wyniku 3772 zaimportowanych wierszy:
Nasz raport wygląda po odświeżeniu następująco:
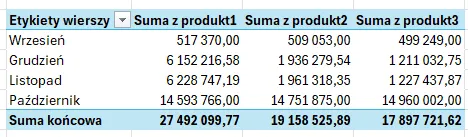
Gotowe! Udało nam się przygotować dynamiczny mechanizm importu danych z wielu wielostronicowych plików PDF.
Podsumowanie
W tym artykule przedstawiliśmy, jak w praktyce podejść do importu danych z wielu plików PDF przy użyciu Power Query. Krok po kroku przygotowaliśmy mechanizm, który automatycznie przetwarza kolejne pliki dodawane do folderu, a przy okazji nauczyliśmy się, jak radzić sobie z typowymi błędami pojawiającymi się przy takim imporcie. Dzięki temu rozwiązaniu nie musimy już ręcznie powtarzać tych samych czynności dla każdego nowego pliku, co pozwoli zaoszczędzić nam wiele czasu.




