


Jak zmienia się złączenie w PowerQuery, gdy damy parametr ListNonNullCount
Power Query
Microsoft Office
Spis treści:
- Zacznijmy od podstaw — czym jest złączenie tabel?
- Przykładowe dane — wyobraź sobie taki scenariusz
- Normalne złączenie — co się dzieje domyślnie?
- Czym jest ListNonNullCount?
- Rozwiązanie — filtrowanie przed złączeniem
- Dlaczego List.NonNullCount, a nie zwykłe <> null?
- Podsumowanie
- Dlaczego nie po prostu Inner Join?
- Scenariusz, w którym Inner Join zawodzi
- Kiedy Inner Join jest jednak ok?
Zacznijmy od podstaw — czym jest złączenie tabel?
Wyobraź sobie, że masz dwie listy w Excelu: jedną z zamówieniami i drugą z danymi klientów. Chcesz je połączyć, żeby przy każdym zamówieniu pojawiło się imię klienta. W Power Query robi się to przez scalanie (merge) — czyli operację, która szuka pasujących wierszy w obu tabelach.
Sprawa prosta, gdy klucz (np. ID klienta) jest unikalny po obu stronach. Problem pojawia się, gdy w jednej lub obu tabelach ten sam klucz pojawia się kilka razy, albo klucz zawiera null.
Przykładowe dane — wyobraź sobie taki scenariusz
Mamy sklep internetowy. Jeden klient może złożyć wiele zamówień, a jeden produkt może trafić do wielu zamówień.
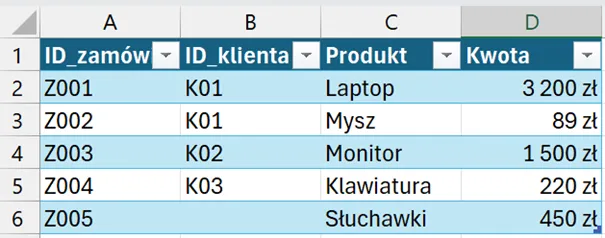
Tabela: Zamówienia — zauważ wiersz Z005 bez przypisanego klienta (null)
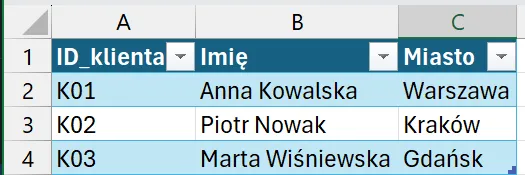
Tabela: Klienci
Normalne złączenie — co się dzieje domyślnie?
Gdy łączysz te tabele przez interfejs Power Query (Narzędzia główne → Scal zapytania), Power Query domyślnie patrzy: „czy wartości kolumny klucza są takie same?”. Domyślne złączenie lewe zewnętrzne (LeftOuter) zachowuje wszystkie wiersze z lewej tabeli. Wiersz Z005 trafia do wyniku — ale kolumny Imię i Miasto są puste, bo nie ma dopasowania.
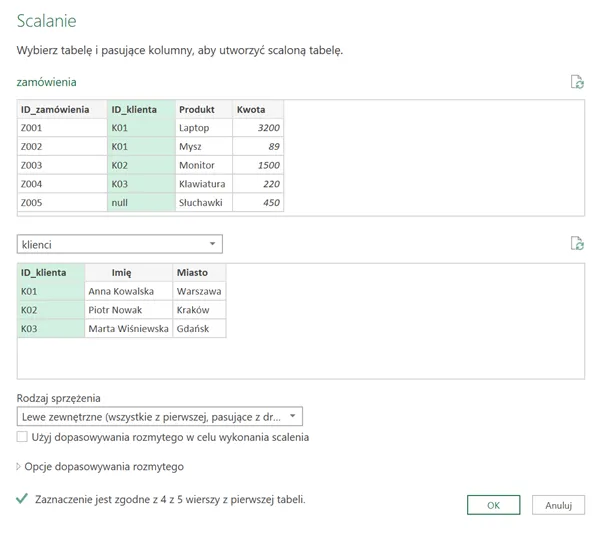
Wynik standardowego złączenia wygląda tak — wiersz Z005 dostaje null w kolumnach klienta, bo jego ID_klienta to null. Jeśli potem zsumujemy sprzedaż według miast — ten wiersz trafi do kategorii „bez miasta” i zaburzy raport.

Domyślne zachowanie: null nie pasuje do null. Power Query traktuje brak wartości jako „nieznany”, a dwa nieznane to nie to samo co jeden. Filozoficznie mądre, praktycznie — czasem kłopotliwe.
PowerQuery kod języka M:
let
Źródło = zamówienia,
scalone = Table.NestedJoin(Źródło, {„ID_klienta”},
klienci,{„ID_klienta”}, „klienci”,
JoinKind.LeftOuter),
scalone_klienci = Table.ExpandTableColumn(scalone, „klienci”, {„Imię”, „Miasto”}, {„Imię”, „Miasto”})
in
scalone_klienci
Czym jest ListNonNullCount?
To funkcja pomocnicza z grupy List.*, która na pierwszy rzut oka wygląda niewinnie:
// List.NonNullCount — zlicza elementy listy, które NIE są null
List.NonNullCount({1, 2, null, 4, null}) // wynik: 3
List.NonNullCount({null, null, null}) // wynik: 0
List.NonNullCount({„A”, „B”, „C”}) // wynik: 3
// sama jedna wartość — null
List.NonNullCount({null}) // wynik: 0
Kluczowa obserwacja: jeśli owiniesz jedną wartość w listę {wartość} i sprawdzisz List.NonNullCount({wartość}) = 1, dostajesz elegancki test: „czy ta wartość nie jest null?”.
Prosta sprawa. Ale co ona ma wspólnego ze złączeniami? Bezpośrednio — nic. To właśnie ta właściwość sprawia, że List.NonNullCount przydaje się przy filtrowaniu przed złączeniem.
Rozwiązanie — filtrowanie przed złączeniem
Zamiast łączyć wszystko i potem zastanawiać się co zrobić z nullami, odfiltrowujemy je przed złączeniem. Dodajemy jeden krok: tylko_z_klientem.

let
Źródło = zamówienia,
// Krok kluczowy: zostawiamy tylko wiersze z niepustym kluczem
tylko_z_klientem = Table.SelectRows(
Źródło,
each List.NonNullCount({[ID_klienta]}) = 1
),
// Teraz złączenie — tylko „czyste” wiersze trafiają do merge
scalone = Table.NestedJoin(
tylko_z_klientem, {„ID_klienta”},
klienci, {„ID_klienta”},
„klienci_dane”, JoinKind.LeftOuter
),
rozwinięte = Table.ExpandTableColumn(scalone, „klienci_dane”, {„Imię”, „Miasto”}, {„Imię”, „Miasto”})
in
rozwinięte
Co robi podświetlona linijka krok po kroku:
- Each — przechodzimy przez każdy wiersz tabeli
- {[ID_klienta]} — owijamy wartość klucza w listę jednoelementową
- List.NonNullCount(…) = 1 — sprawdzamy, czy ta lista ma dokładnie jeden niepusty element (czyli czy klucz nie jest null)
- Table.SelectRows — zachowuje tylko wiersze, dla których warunek jest prawdziwy
Wynik — co się zmieniło?

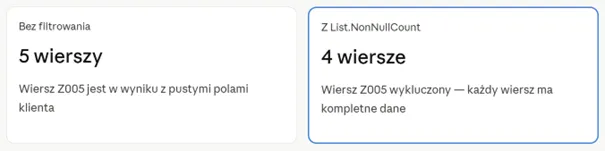
Teraz możemy bezpiecznie zgrupować dane według miast. Żaden wiersz nie „wpadnie” do kategorii „bez miasta”, bo odfiltrowaliśmy problem u źródła.
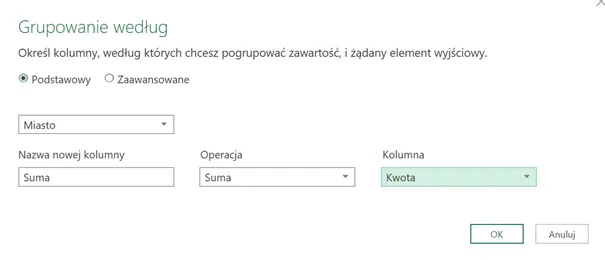
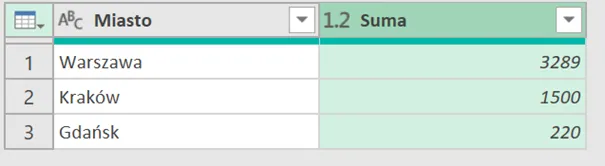
Zamówienie Z005 (Słuchawki, 450 zł) nie trafiło do raportu — brak klienta, brak miasta.
Dlaczego List.NonNullCount, a nie zwykłe <> null?
Dobre pytanie. Można by napisać prościej:
// Prostszy zapis — działa identycznie dla jednej kolumny
tylko_z_klientem = Table.SelectRows(Źródło, each [ID_klienta] <> null),
// List.NonNullCount błyszczy, gdy sprawdzamy WIELE kolumn naraz
kompletne_wiersze = Table.SelectRows(Źródło,
each List.NonNullCount({[ID_klienta], [Produkt], [Kwota]}) = 3
),
Dla jednej kolumny <> null jest prostszy i czytelniejszy. List.NonNullCount naprawdę się opłaca, gdy chcesz sprawdzić kilka kolumn naraz. Zamiast pisać długi warunek z wieloma and, wrzucasz wszystkie kolumny do listy i sprawdzasz, czy liczba niepustych równa się liczbie kolumn.
Zasada: List.NonNullCount({[A],[B],[C]}) = 3 oznacza „wszystkie trzy kolumny są wypełnione”. Zmień 3 na 1 i dostajesz „przynajmniej jedna jest wypełniona”.
Kiedy używać, a kiedy nie?
- Sprawdzanie jednej kolumny na null → [Kolumna] <> null jest prostsze
- Sprawdzanie wielu kolumn naraz → List.NonNullCount wygrywa czytelnością
- Liczenie wypełnionych pól w wierszu (np. „ile z 10 kolumn ma wartość?”) → List.NonNullCount to idealne narzędzie
- Filtrowanie przed złączeniem → oba podejścia działają, wybierz to, które jest czytelniejsze dla Twojego zespołu
Podsumowanie
Podejście
Wiersz z null w kluczu
Wynik złączenia
Standardowe LeftOuter
trafia do wyniku
5 wierszy, null po stronie klienta
SelectRows + List.NonNullCount = 1
odfiltrowany przed merge
4 wiersze, każdy z pełnymi danymi
Dobra praktyka: filtruj nulle przed złączeniem, nie po. Raport jest czystszy, zapytanie szybsze (mniej wierszy do złączenia), a intencja kodu jest jasna dla każdego, kto go przeczyta.
Dlaczego nie po prostu Inner Join?
To bardzo naturalne pytanie. Skoro i tak chcemy tylko wiersze z dopasowanym klientem — po co filtrować przed złączeniem? Wystarczy zmienić lewe zewnętrzne JoinKind.LeftOuter na wewnętrzne JoinKind.Inner, prawda?
Prawie. W wielu przypadkach wynik będzie identyczny — ale są sytuacje, w których Inner Join zachowa się inaczej niż się spodziewasz i to w sposób trudny do wykrycia.
Scenariusz, w którym Inner Join zawodzi
Dodajmy do naszych danych jeden nowy wiersz — klienta K04, który jest w tabeli zamówień, ale nie ma go w tabeli klientów (np. dane z innego systemu jeszcze nie dotarły):
ID_zamówienia
ID_klienta
Produkt
Kwota
Z001
K01
Laptop
3 200 zł
Z002
K01
Mysz
89 zł
Z003
K02
Monitor
1 500 zł
Z004
K03
Klawiatura
220 zł
Z005
null
Słuchawki
450 zł
Z006
K04
Tablet
1 800 zł
Teraz porównaj, co zwróci każde podejście:
Inner Join
JoinKind.Inner
Zalecane:
SelectRows + LeftOuter
Zachowuje tylko wiersze z dopasowaniem po obu stronach. Z005 (null) odpada — ale Z006 (K04) też odpada, bo K04 nie ma w tabeli klientów.
Cicha utrata danych — Z006 znika bez ostrzeżenia
Filtrujemy tylko nulle. Z006 (K04) trafia do wyniku — z pustymi polami imienia i miasta, ale wiersz jest widoczny.
Problem z K04 jest widoczny — można go naprawić
Wyniki obu podejść dla naszych 6 wierszy:
| ID_zamówienia | ID_klienta | Produkt | Imię | Inner Join | SelectRows + LeftOuter |
|---|---|---|---|---|---|
| Z001 | K01 | Laptop | Anna Kowalska | jest | jest |
| Z002 | K01 | Mysz | Anna Kowalska | jest | jest |
| Z003 | K02 | Monitor | Piotr Nowak | jest | jest |
| Z004 | K03 | Klawiatura | Marta Wiśniewska | jest | jest |
| Z005 | null | Słuchawki | — | brak | brak |
| Z006 | K04 | Tablet | brak w klientach | ZNIKNĄŁ | jest (null) |
To jest pułapka Inner Join: usuwa nie tylko nulle, ale też wszystkie wiersze bez dopasowania — w tym błędne klucze, nowe rekordy jeszcze niezsynchronizowane, literówki w ID. Błąd jest niemy — raport po prostu ma mniejszą kwotę, a Ty nie wiesz dlaczego.
Kiedy Inner Join jest jednak ok?
Jest jedno założenie, przy którym Inner Join jest bezpieczny: masz pewność, że każdy niepusty klucz w tabeli zamówień ma odpowiednik w tabeli klientów. Dzieje się tak gdy:
- obie tabele pochodzą z tej samej bazy danych z kluczami obcymi (relacyjna integralność gwarantuje dopasowanie)
- dane są ręcznie przygotowane i zweryfikowane
- raportujesz historyczne, zamknięte dane, które się już nie zmienią
W każdym innym przypadku — czyli w większości realnych projektów Power Query opartych na plikach, API czy eksportach z różnych systemów — LeftOuter z wcześniejszym filtrowaniem nullów jest bezpieczniejszy, bo pokazuje problemy zamiast je ukrywać.
Zasada: Inner Join milczy, gdy traci dane. LeftOuter z filtrem na null mówi głośno — widzisz nullowe wiersze w wyniku i wiesz, że coś wymaga uwagi. W produkcyjnych raportach wolisz wiedzieć o problemie niż mieć „czysty” wynik z błędem w sumach.

Automatyzacja zadań w Excelu 365 - skrypty TypeScript

Porównanie Google Sheets vs Excel – jakie narzędzie wybrać?

Niedoceniana funkcja SUMA.ILOCZYNÓW. Jak tworzyć rankingi?

Microsoft Power Apps – co to jest, jak działa i kiedy zastępuje Excela
