


Window Functions w SQL – niedoceniane narzędzie analityka
SQL
Spis treści:
- Wstęp
- Na czym polegają funkcje okna?
- Fundament funkcji okna – klauzula OVER()
- Sumy narastające
- Podwójna agregacja z GROUP BY
- Średnie kroczące
- Funkcje przesunięcia – LAG i LEAD
- Przykład użycia LAG()
- Przykład użycia LEAD()
- Funkcje szeregujące (rankingowe)
- Funkcja ROW_NUMBER()
- Funkcja RANK() – ranking nieciągły
- Funkcja DENSE_RANK() – ranking ciągły
- Podsumowanie
Wstęp
W codziennej pracy z bazami danych często zderzamy się z ograniczeniami standardowych funkcji agregujących. Użycie klauzuli GROUP BY świetnie podsumowuje informacje, ale bezpowrotnie zwija wiersze, ukrywając przed nami detale pojedynczych transakcji. Próba wyświetlenia szczegółowych rekordów obok zagregowanych danych dla całej grupy zmusza nas do pisania nieoptymalnych zapytań. Rozwiązaniem tego architektonicznego problemu są funkcje okna.
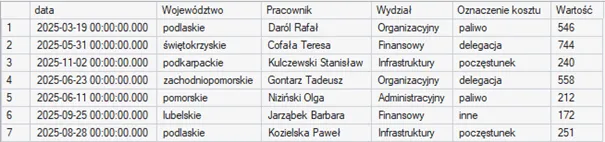
Aby zobrazować działanie funkcji okna skorzystamy z przykładowej tabeli budzet. Przechowuje ona dane o wydatkach – data operacji, pracownik, wydział, oznaczenie kosztu oraz jego wartość:
Na czym polegają funkcje okna?
Funkcje okna to zaawansowany mechanizm w języku SQL, który pozwala na wykonywanie obliczeń na wydzielonym podzbiorze wierszy – zwanym „oknem” – powiązanym z bieżącym rekordem. W przeciwieństwie do standardowych funkcji agregujących, funkcje okna nie redukują liczby zwracanych wierszy. Dzięki temu w jednym raporcie możemy zobaczyć np. pojedynczą transakcję oraz zagregowaną wartość dla całego jego działu.
Przykłady opisane poniżej, oparte są o bazę danych Microsoft SQL Server.
Fundament funkcji okna – klauzula OVER()
Aby zdefiniować obszar, w jakim funkcja ma operować, używamy klauzuli OVER(). W jej wnętrzu możemy ustalić parametry, które określają zasięg obliczeń:
Brak parametrów
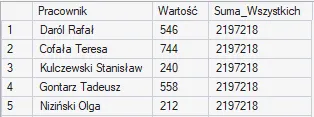
Brak przekazanych parametrów oznacza, że naszym oknem staje się cała tabela. W tym przypadku do każdego wiersza zostanie przypisana całkowita suma wszystkich wydatków:
💡 Ciekawostka:
Włączenie klauzuli OVER() sprawia, że zestawienie w jednym zapytaniu szczegółowych kolumn (takich jak pracownik czy wartość) z wynikiem agregacji – np. SUM(Wartość) – nie wymusza na nas stosowania GROUP BY. To właśnie na tym polega największa przewaga funkcji okna nad klasycznym grupowaniem danych.
Włączenie klauzuli OVER() sprawia, że zestawienie w jednym zapytaniu szczegółowych kolumn (takich jak pracownik czy wartość) z wynikiem agregacji – np. SUM(Wartość) – nie wymusza na nas stosowania GROUP BY. To właśnie na tym polega największa przewaga funkcji okna nad klasycznym grupowaniem danych.
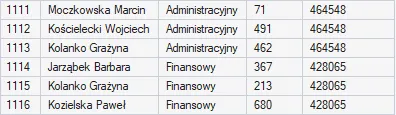
PARTITION BY

PARTITION BY dokonuje logicznego podziału zbioru danych na niezależne sekcje (partycje). Kiedy system napotyka nowy segment (np. inny wydział), resetuje swoje obliczenia i rozpoczyna je od nowa (w tym przypadku sumę wartości dla danego wydziału):
ORDER BY
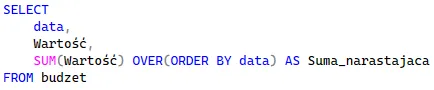
Wprowadzenie ORDER BY wewnątrz okna sprawia, że wartości są przetwarzane sekwencyjnie. Baza nie zwraca od razu pełnej sumy, lecz dodaje kolejne koszty krok po kroku, zgodnie z osią czasu. To nic innego jak obliczanie sumy narastającej w pełnym zbiorze danych:
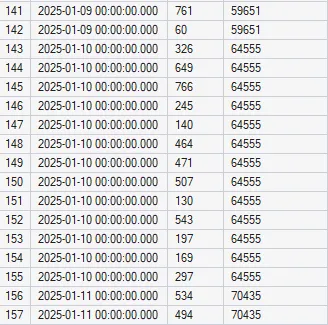
Sumy narastające
Wykorzystując połączenie PARTITION BY i ORDER BY możemy zastosować tzw. Sumy narastające. Taka struktura jest bardzo przydatna, gdy chcemy np. sprawdzić, w którym dniu każdy dział przekroczył określony próg finansowy:

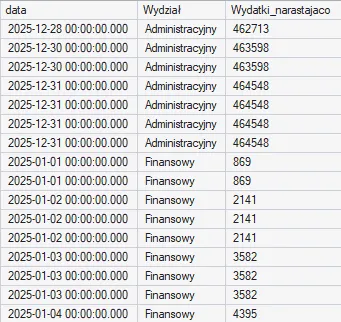
Dzięki jednoczesnemu użyciu PARTITION BY i ORDER BY, baza danych nie sumuje kosztów wydziału naraz, lecz wartości dodawane są krok po kroku (chronologicznie według kolumny data).
Podwójna agregacja z GROUP BY
Jeżeli chcielibyśmy użyć funkcji okna na danych, które musimy pogrupować (np. chcemy obliczyć procentowy udział danego wydziału w całkowitych kosztach), musimy nałożyć funkcję okna na standardową agregację:
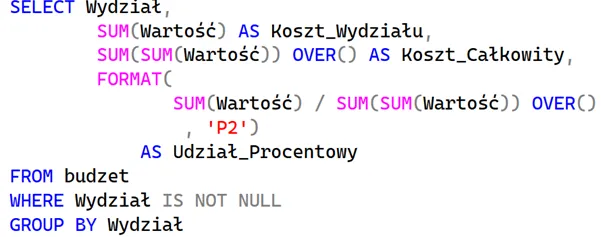
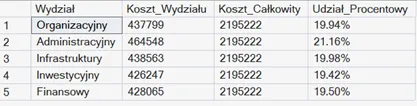
Bez „podwójnej” agregacji system zwróciłby błąd składni, ponieważ funkcja okna uruchamia się w ostatniej fazie przetwarzania zapytania.
Średnie kroczące
Domyślnie dodanie klauzuli ORDER BY sprawia, że funkcja okna liczy wartości od samego początku partycji aż do bieżącego rekordu. W analityce często potrzebujemy jednak węższego spojrzenia – na przykład po to, aby wygładzić nagłe skoki kosztów za pomocą 7-dniowej średniej kroczącej. Do precyzyjnego i dynamicznego zawężania naszej ramki obliczeniowej służy dyrektywa ROWS BETWEEN.
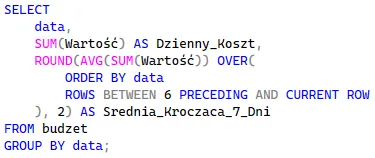
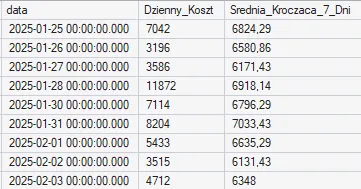
Użycie konstrukcji 6 PRECEDING AND CURRENT ROW tworzy dynamiczne okno (obecny wiersz plus 6 poprzednich), które płynnie przesuwa się w dół z każdym kolejnym rekordem.
Funkcje przesunięcia – LAG i LEAD
W analityce często musimy zestawić dane z bieżącego wiersza z tym, co wydarzyło się wcześniej lub później – na przykład, aby sprawdzić, czy kolejny wydatek pracownika był wyższy od poprzedniego. W klasycznym SQL-u wymagałoby to skomplikowanego łączenia tabeli z samą sobą. Funkcje okna rozwiązują to znacznie prościej za pomocą poleceń LAG() (wstecz) oraz LEAD() (w przód).
Obie funkcje przyjmują trzy parametry: kolumna, offset (o ile wierszy mamy się przesunąć, domyślnie 1) i wartość_domyślna (co ma się pojawić, jeśli nie ma następnego/poprzedniego wiersza).
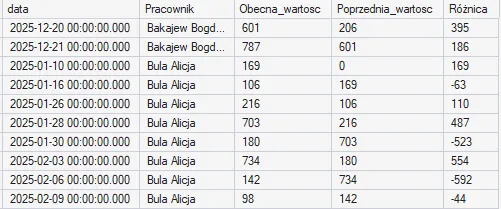
Przykład użycia LAG()
Załóżmy, że chcemy przeanalizować historię wydatków każdego pracownika i zobaczyć, jak zmieniały się z dnia na dzień:

Przykład użycia LEAD()
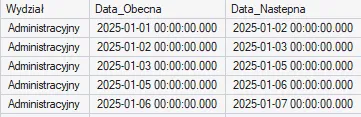
Funkcja LEAD() działa identycznie, ale odnosi się do wierszy w przód. Możemy jej użyć, aby np. sprawdzić, kiedy nastąpił kolejny wydatek w danym wydziale:

Funkcje szeregujące (rankingowe)
Funkcje szeregujące (rankingowe) służą do przypisywania pozycji każdemu wierszowi w zdefiniowanej partycji na podstawie określonej kolejności. Wyznaczają pozycję danego wiersza porównując go z wartościami innych wierszy (w tej samej partycji).
Funkcja ROW_NUMBER()
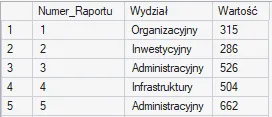
Podstawowym narzędziem szeregującym jest ROW_NUMBER(), które nadaje unikalny, sekwencyjny numer każdemu wierszowi, całkowicie ignorując remisy (nawet przy takich samych wartościach numeracja rośnie: 1, 2, 3…).
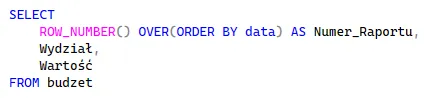
Możemy użyć tej funkcji globalnie, podając w OVER() samo ORDER BY, co posłuży nam do prostego ponumerowania wszystkich wierszy w raporcie:
Możemy również skorzystać z PARTITION BY, aby np. numerować transakcje wewnątrz każdego wydziału:

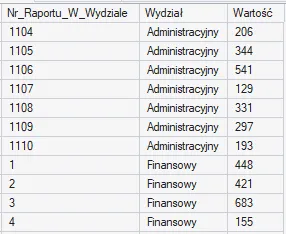
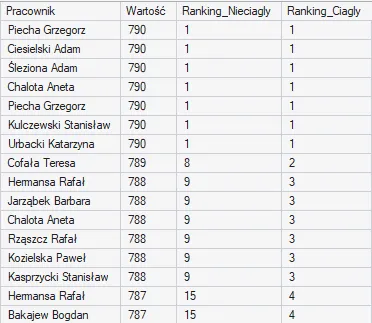
Funkcja RANK() – ranking nieciągły
Funkcja RANK() to podstawowe narzędzie do tworzenia rankingów, które przypisuje ten sam numer (rangę) wierszom z remisami.
Staje się to problematyczne, gdy chcemy stworzyć rzeczywisty ranking np. najwyższych kosztów, a niektóre wydatki w tabeli mają dokładnie taką samą wartość. Jeśli zastosujemy tę funkcję, oba zremisowane rekordy otrzymają zasłużenie to samo miejsce (np. pozycję 2).
Funkcja ta tworzy jednak ranking nieciągły. Oznacza to, że uwzględnia ona liczbę wierszy, które już przetworzyła. Jeśli dwa wiersze zajęły miejsce 2, system „rezerwuje” miejsce 3, a kolejny, tańszy wydatek otrzymuje od razu pozycję 4. Powstaje w ten sposób nielogiczna „dziura” w numeracji:
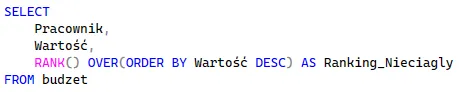
Funkcja DENSE_RANK() – ranking ciągły
Aby zachować ścisłą ciągłość numeracji i wyeliminować luki, stosujemy funkcję DENSE_RANK(), która tworzy ranking ciągły. W przypadku takich samych wartości, funkcja również przyzna obu wierszom pozycję 2, ale kolejny wydatek w zestawieniu otrzyma sprawiedliwą pozycję 3.
Zestawiając obie funkcje obok siebie, błyskawicznie zauważymy różnicę w ich mechanice:
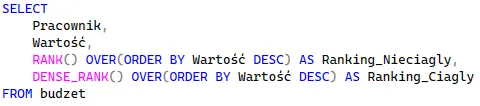
Podsumowanie
Funkcje okna to bez wątpienia jedno z najbardziej wszechstronnych narzędzi w świecie SQL. Dzięki nim analitycy mogą budować zaawansowane raporty, zachowując idealny balans między ogólnym trendem a detalami pojedynczych rekordów. Opanowanie klauzuli OVER() pozwala zrezygnować z pisania skomplikowanych podzapytań na rzecz czytelnego i wydajnego kodu. Te oraz wiele innych zagadnień związanych z SQL-em wyjaśniamy na praktycznych przykładach w Imperium Szkoleniowym. To tam pokazujemy, jak przekuć surowe dane w wartościową wiedzę biznesową.




