


Jakie zapytania SQL są najczęściej używane w pracy analityka?
SQL
Analityka danych
Spis treści:

Każdego dnia w pracy analityka nurkujemy w ogromnym oceanie danych. Często zastanawiamy się, od czego zacząć, gdy widzimy przed sobą setki tysięcy wierszy. Z pomocą przychodzi nam SQL – nasz najprostszy i najskuteczniejszy język komunikacji z bazą. Nie musimy od razu pisać skomplikowanych skryptów na setki linijek. W rzeczywistości, przez większość czasu opieramy się na kilku sprawdzonych komendach.
W bazie danych mamy tabelę główną „dane” (zawierającą m.in. Identyfikator, Wartość, Rejon, Zlecenie). Zobaczmy, po jakie komendy sięgamy najczęściej, żeby sprawnie wyciągnąć z tej struktury cenną wiedzę!
Wybieramy konkrety i liczymy: SELECT, aliasy i obliczenia
Zaczynamy od wyciągnięcia informacji z naszej głównej tabeli dane. Używamy klauzuli SELECT, by wskazać interesujące nas kolumny. Często chcemy od razu zmienić nazwę kolumny na bardziej czytelną w raporcie – robimy to za pomocą aliasu AS. Co więcej, SQL pozwala nam wykonywać matematykę „w locie”, co świetnie sprawdza się przy szybkich obliczeniach wartości brutto, podatków czy marży.
SQL:
SELECT
Identyfikator AS id_transakcji,
Zlecenie,
Wartość,
Wartość * 1.23 AS wartosc_brutto
FROM dane;
SELECT
Identyfikator AS id_transakcji,
Zlecenie,
Wartość,
Wartość * 1.23 AS wartosc_brutto
FROM dane;
Dzięki temu wyciągamy tylko to, co nas interesuje, od razu w gotowej do analizy formie.
Odcinamy szum: WHERE
Zazwyczaj nie analizujemy całej bazy naraz. Interesuje nas konkretny wycinek, na przykład zlecenia z danego rejonu o określonej wartości. Wtedy z pomocą przychodzi WHERE. To nasz filtr, którym błyskawicznie zawężamy wyniki do niezbędnego minimum, dzięki czemu oszczędzamy w ten sposób mnóstwo czasu i kosztów, jeśli silnik bazy danych rozlicza nas za każdą przesłaną paczkę danych.
SQL:
SELECT Zlecenie, Wartość
FROM dane
WHERE Rejon = 'Południe’ AND Wartość > 5000;
SELECT Zlecenie, Wartość
FROM dane
WHERE Rejon = 'Południe’ AND Wartość > 5000;
Odrzucamy w ten sposób niepotrzebne wiersze i oszczędzamy mnóstwo czasu, pracując tylko na konkretach.

Podsumowujemy wyniki: GROUP BY i HAVING
Same surowe wiersze rzadko dają nam pełen obraz biznesowy. Aby sprawdzić, które województwa generują dla nas największe wartości, musimy pogrupować informacje. Wykorzystujemy do tego GROUP BY oraz agregację (np. SUM lub AVG). A jeśli interesują nas tylko te województwa, w których zrobiliśmy naprawdę duży obrót? Dokładamy klauzulę HAVING, która filtruje już pogrupowane wyniki. Zamieniamy tysiące pojedynczych transakcji w czytelne raporty.
SQL:
SELECT Województwo,
SUM(Wartość) AS suma_sprzedazy
FROM dane
GROUP BY Województwo
HAVING SUM(Wartość) > 100000;
SELECT Województwo,
SUM(Wartość) AS suma_sprzedazy
FROM dane
GROUP BY Województwo
HAVING SUM(Wartość) > 100000;
Grupujemy, podsumowujemy i od razu odsiewamy słabsze rynki. Czysto i na temat!
Porządek na końcu: ORDER BY
Nasze wyniki muszą być czytelne. Nikt nie lubi szukać największych wartości przemieszanych z najmniejszymi. Używając na końcu zapytania ORDER BY, układamy dane rosnąco lub malejąco (dzięki dopiskowi DESC).
SQL:
SELECT Klient, Wartość
FROM dane
ORDER BY Wartość DESC;
SELECT Klient, Wartość
FROM dane
ORDER BY Wartość DESC;
Dzięki temu najwyższe wartości zleceń zawsze mamy na samej górze naszego zestawienia.
Łączymy rozsypane dane w całość: relacje i LEFT JOIN
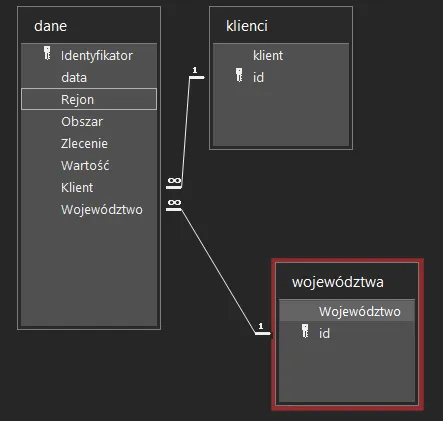
Połączone tabele relacjami
Poprzednie przykłady miały jeden haczyk – zakładały, że wszystkie informacje leżą grzecznie w jednej, „płaskiej” tabeli, niczym w prostym arkuszu kalkulacyjnym. W prawdziwym świecie systemów biznesowych bazy danych tak nie wyglądają. Opierają się na relacjach. Klienci mają swoją tabelę, województwa swoją, a konkretne pozycje na fakturze jeszcze inną. Takie rozbicie danych gwarantuje porządek, ale jak z tego gąszczu wyciągnąć spójne wnioski?
Aby wyciągnąć z nich spójne wnioski, musimy je połączyć za pomocą instrukcji LEFT JOIN. Pozwala nam ona wziąć naszą główną tabelę dane i dokleić do niej pasujące rekordy z kolejnych tabel (klienci i województwa), dając przy tym pewność, że żaden rekord z tabeli bazowej nam nie zniknie.
SQL:
SELECT
d.Rejon,
k.klient,
COUNT(d.*) AS liczba_transakcji,
SUM(d.Wartość) AS suma_przychodu
FROM dane d
LEFT JOIN województwa w ON w.id = d.Województwo
LEFT JOIN klienci k ON k.id = d.Klient
WHERE w.Województwo = 'mazowieckie’
GROUP BY k.klient, d.Rejon
HAVING COUNT(*) > 10
ORDER BY suma_przychodu DESC;
SELECT
d.Rejon,
k.klient,
COUNT(d.*) AS liczba_transakcji,
SUM(d.Wartość) AS suma_przychodu
FROM dane d
LEFT JOIN województwa w ON w.id = d.Województwo
LEFT JOIN klienci k ON k.id = d.Klient
WHERE w.Województwo = 'mazowieckie’
GROUP BY k.klient, d.Rejon
HAVING COUNT(*) > 10
ORDER BY suma_przychodu DESC;
W ten sposób, używając grupowania, filtrów przed i po agregacji (WHERE oraz HAVING), sortowania, wyciągamy precyzyjne dane z trzech oddzielnych tabel i błyskawicznie budujemy gotowy do analizy raport.
Organizujemy skomplikowane myśli: klauzula WITH
Gdy nasze zapytania rosną i robią się wieloetapowe, z pomocą przychodzi konstrukcja WITH (tzw. CTE). Pozwala nam ona stworzyć „wirtualną”, tymczasową tabelę w pamięci, do której odwołamy się krok dalej. Robimy to, aby nasz kod pozostał logiczny i czytelny.
SQL:
WITH Duzi_Klienci AS (
SELECT k.klient, SUM(d.Wartość) AS suma_zamowien
FROM dane d
LEFT JOIN klienci k ON k.id = d.Klient
GROUP BY k.klient
HAVING SUM(d.Wartość) > 50000
)
SELECT * FROM Duzi_Klienci
ORDER BY suma_zamowien DESC;
WITH Duzi_Klienci AS (
SELECT k.klient, SUM(d.Wartość) AS suma_zamowien
FROM dane d
LEFT JOIN klienci k ON k.id = d.Klient
GROUP BY k.klient
HAVING SUM(d.Wartość) > 50000
)
SELECT * FROM Duzi_Klienci
ORDER BY suma_zamowien DESC;
W ten sposób rozbijamy duży analityczny problem na małe, łatwe do przetrawienia klocki.
Podsumowanie – dlaczego zyskujemy pracując z SQL?

Biegłe posługiwanie się tymi kilkoma komendami to nasz duży atut. Zamiast czekać, aż arkusz kalkulacyjny przetworzy tysiące wierszy, wyciągamy precyzyjne wnioski z bazy w ułamku sekundy. Optymalizujemy naszą pracę, oszczędzamy cenne godziny i podejmujemy trafne decyzje, które opierają się na bezbłędnych faktach. SQL pozwala nam przejąć pełną kontrolę nad danymi.
Poznaj SQL z Imperium Szkoleniowym!
Czujesz, że samodzielna nawigacja po strukturach bazodanowych to wciąż czarna magia? W Imperium Szkoleniowym z przyjemnością rozwiążemy Twoje problemy! Pomożemy Ci okiełznać język SQL i nauczymy, jak od zera wyciągać bezcenną wiedzę biznesową. Razem zmigrujemy Twoje umiejętności na zupełnie nowy poziom ekspercki. Oszczędzamy Twój czas, skupiając się na praktyce i twardych konkretach. Sprawdź naszą ofertę – krok po kroku zrobimy z Ciebie mistrza analizy danych!

Git dla analityków danych – dlaczego Excel nie wystarcza do kontroli wersji?

Czy BigQuery to dobre rozwiązanie analityczne dla średniej firmy?

Window Functions w SQL – niedoceniane narzędzie analityka

SQL w BigQuery – czym różni się od klasycznego SQL?
