
Jak wygląda migracja danych do BigQuery krok po kroku?
BigQuery
Analityka danych
Spis treści:
- Faza 1: Audyt i sprzątanie. Czego nie przenosisz do BigQuery?
- Faza 2: Konfiguracja Google Cloud Platform (GCP) krok po kroku
- Faza 3: Migracja MS Excel i plików CSV do BigQuery. Najszybsze zwycięstwo
- Faza 4: Wyzwanie – baza danych SQL i przenoszenie dużych zbiorów
- Faza 5: Modelowanie danych w BigQuery. Budowa jednej wersji prawdy
- Faza 6: Utrzymanie i automatyzacja. Niech to działa samo
- Koszty i optymalizacja: Jak nie zbankrutować, używając BigQuery
- Podsumowanie i kolejne kroki. (A co powiesz na Looker Studio?)
- Potrzebujesz wsparcia? Zróbmy to razem!
Zastanawialiście się kiedyś, ile godzin w miesiącu tracimy na wpatrywanie się w pasek ładowania w Excelu? Zapewne każdy z nas, kto kiedykolwiek pracował z danymi, doszedł do ściany, za którą kończą się możliwości tradycyjnych arkuszy kalkulacyjnych. Kiedy pliki zaczynają ważyć setki megabajtów, a my przed każdym odświeżeniem raportu musimy zamknąć wszystkie inne programy, żeby nie zawiesić komputera, to znak, że czas na zmiany. Właśnie dlatego coraz częściej uciekamy do chmury. Przejście z lokalnych rozwiązań na infrastrukturę chmurową to nie tylko modny trend, ale przede wszystkim konieczność biznesowa, jeśli chcemy zachować zdrowy rozsądek i ciągłość pracy.
W sercu tej chmurowej rewolucji, przynajmniej w ekosystemie Google, leży BigQuery. Zanim jednak rzucimy się w wir konfiguracji, odpowiedzmy sobie prostym językiem, czym to narzędzie w ogóle jest. BigQuery to bezserwerowa hurtownia danych. Słowo „bezserwerowa” (serverless) jest tu kluczowe – oznacza, że nie interesuje nas, na jakim sprzęcie to działa, ile ma procesorów ani czy trzeba dokupić kości RAM. My po prostu wrzucamy tam dane, a Google martwi się o całą resztę. Płacimy tylko za to, co faktycznie przechowujemy, i za zapytania, które wykonujemy.
Dlaczego uciekamy do chmury właśnie z użyciem BigQuery? Przede wszystkim dla świętego spokoju. Odpadają nam problemy z utrzymaniem infrastruktury, aktualizacjami oprogramowania czy brakiem miejsca na dysku. Chmura daje nam elastyczność – jeśli jutro nasza baza danych urośnie z gigabajta do petabajta, BigQuery nawet nie dostanie zadyszki. Skaluje się automatycznie w ułamkach sekund. Co więcej, chmura rozwiązuje problem, który od lat trapi działy analityczne: demokratyzację danych. Wszyscy uprawnieni użytkownicy mają dostęp do tego samego, jednego źródła prawdy, niezależnie od tego, czy pracują z biura w Warszawie, czy z kawiarni na drugim końcu świata.
W tym artykule przejdziemy przez cały proces. Nie będziemy rzucać skomplikowanymi definicjami architektury systemów informatycznych. Zamiast tego, zrobimy to krok po kroku, na konkretnym, życiowym przykładzie. Zobaczymy, jak wyplątać się z sieci lokalnych plików i przejść na jasną stronę mocy. Przeanalizujemy nasz punkt wyjścia, posprzątamy bałagan, założymy środowisko i przeprowadzimy właściwą migrację. Na koniec zadbamy o to, aby ten nowy system działał sam, bez naszego codziennego klikania.

Poznaj nasz przypadek: Zderzenie z rzeczywistością
Zanim przejdziemy do klikania, nakreślmy tło naszej historii, bo bez tego trudno zrozumieć ból, z którym się zmagamy. Wyobraźmy sobie całkiem standardową firmę, która codziennie przetwarza tysiące transakcji. Dane o sprzedaży, zapasach i zamówieniach żyją w potężnym systemie IT – to może być SAP, Microsoft Dynamics albo jakikolwiek inny system ERP. Niestety, dostęp do bazy danych tego systemu jest ściśle chroniony, a my, jako analitycy, dostajemy dane w formie zrzutów. Co poniedziałek rano na nasz serwer plikowy lądują wielkie, ciężkie pliki CSV z danymi z całego poprzedniego tygodnia.
Z tymi plikami CSV jest jeden zasadniczy problem – panuje w nich absolutny bałagan. SAP wyrzuca dane tak, jak mu wygodnie, a nie tak, jak potrzebuje tego biznes do analizy. Mamy tam puste kolumny, dziwne formaty dat (np. tekstowe „20231201”), zduplikowane wiersze i wartości, które zamiast liczbą, są tekstem ze spacją w środku. Z tygodnia na tydzień tych plików przybywa, a każdy kolejny to kilkadziesiąt megabajtów czystego chaosu. Początkowo radziliśmy sobie z tym w jedyny znany nam sposób – używając Power Query (PQ) w Excelu.
Początki z Power Query były świetne. Podłączyliśmy folder z plikami CSV, napisaliśmy kilka kroków czyszczących, usunęliśmy zbędne kolumny, zmieniliśmy typy danych. Wszystko działało, dopóki plików było kilka. Kiedy jednak uzbierało się ich kilkadziesiąt z całego roku, wydajność tego rozwiązania drastycznie spadła. Odświeżenie modelu w Power Query zaczęło zajmować dłuuuuugie minuty. Komputer wył z wysiłku, pamięć RAM była zapchana pod korek, a my mogliśmy tylko iść na bardzo dużą kawę, modląc się, żeby Excel się nie zamknął z błędem o braku zasobów.
Druga, równie bolesna kwestia, to dystrybucja takich raportów. Kiedy stworzyliśmy już piękny plik raportowy (Excel z podpiętym Power Query i tabelami przestawnymi) i wysłaliśmy go mailem lub wrzuciliśmy na firmowego SharePointa, zaczynały się schody. Gdy menedżer na swoim komputerze próbował kliknąć „Odśwież”, otrzymywał radosny komunikat o błędzie. Dlaczego? Ponieważ Power Query w pliku sztywno trzymało ścieżkę dostępu do plików źródłowych, np. C:\Users\Kowalski\Desktop\Dane_SAP. Kolega tej ścieżki u siebie nie miał. Musieliśmy więc kombinować z parametrami, dynamicznymi ścieżkami, co tylko komplikowało już i tak niestabilny plik.
Brak centralnego dostępu do danych źródłowych stał się wąskim gardłem całej organizacji. Jeśli ktoś przeniósł folder z plikami CSV do innego podkatalogu, wszystkie raporty oparte na Power Query natychmiast przestawały działać. Naprawianie tego wymagało ręcznej edycji zapytania. Spędzaliśmy więcej czasu na łataniu infrastruktury plikowej niż na faktycznej analizie danych i wyciąganiu wniosków. Miarka się przebrała – zdaliśmy sobie sprawę, że to nie jest rozwiązanie, które pozwoli nam rosnąć. Musieliśmy poszukać czegoś szybszego, stabilniejszego i scentralizowanego. Padło na BigQuery.

Faza 1: Audyt i sprzątanie. Czego nie przenosisz do BigQuery?
Zanim zaczniemy cokolwiek migrować do chmury, musimy zrobić krok w tył i spojrzeć na to, co właściwie posiadamy. Najgorsze, co możemy zrobić podczas jakiejkolwiek migracji – czy to przeprowadzki do nowego mieszkania, czy do BigQuery – to zabranie ze sobą starych śmieci. Jeśli przeniesiemy bałagan z lokalnego dysku do chmury, jedyne co zyskamy, to znacznie droższy i szybszy bałagan. Dlatego Faza 1 to bezwzględny audyt i generalne porządki. Zaczynamy od inwentaryzacji naszych zasobów.
Musimy odpowiedzieć sobie na pytanie: z jakich źródeł obecnie korzystamy? W naszej firmie mamy prawdziwy miks technologiczny. Część danych to wspomniane nieszczęsne zrzuty CSV z systemu IT. Część historycznych danych leży na starym, powoli działającym Microsoft SQL Serverze, który ktoś kiedyś postawił pod biurkiem. Mamy też mnóstwo tak zwanych „baz danych” w arkuszach Excela – plikach tworzonych ręcznie przez dział marketingu czy HR, które zawierają kluczowe informacje, np. mapowania kodów produktów na kategorie promocyjne. Zbieramy to wszystko w jeden wielki rejestr źródeł.
Kiedy mamy już listę, zaczynamy proces kategoryzacji. Bierzemy pod lupę stare tabele w MS SQL Server. Zauważamy tam tabele tymczasowe, kopie zapasowe z 2018 roku, tabele z dopiskiem „_FINAL_v3_DO_NIE_KASOWANIA”. Tego zdecydowanie nie migrujemy. Do BigQuery przenosimy tylko te zbiory, które niosą wartość analityczną i są aktualne. Decydujemy, które dane historyczne są nam faktycznie potrzebne – czy musimy mieć w chmurze paragony z 2015 roku, jeśli analizujemy tylko trendy z ostatnich trzech lat? Często okazuje się, że 40% danych ze starej bazy można bez żalu zarchiwizować na dysku.
Podobną, bezlitosną weryfikację przechodzą arkusze Excela. Zamiast migrować każdy plik, w którym ktoś wpisał trzy liczby, wybieramy tylko te, które pełnią rolę kluczowych słowników (tzw. tabele wymiarów – dimension tables). Jeśli marketing ma plik Excela z celami sprzedażowymi, musimy go najpierw ustandaryzować. Zdejmujemy scalone komórki, usuwamy ładne kolorki i formatowania, pozbywamy się pustych wierszy oddzielających sekcje. Tworzymy płaską, nudną, ale poprawną strukturalnie tabelę, którą system bazodanowy będzie w stanie bezbłędnie odczytać.
Kolejnym krokiem w tej fazie jest analiza naszych plików CSV z systemu IT. Zanim je wgramy, musimy zrozumieć ich strukturę. Jakiego separatora użyto (przecinek, średnik, tabulator)? W jakim kodowaniu zapisano plik (UTF-8, Windows-1250), by uniknąć krzaków zamiast polskich znaków? Musimy też ustalić, jak potraktujemy błędy w danych. W Power Query ręcznie korygowaliśmy każdą anomalię, ale w BigQuery chcemy ten proces zautomatyzować. Tworzymy więc listę powtarzających się problemów z plikami CSV, aby w kolejnych fazach napisać odpowiednie zapytania SQL, które same oczyszczą te dane już po stronie chmury.
Audyt to także odpowiedni moment na rozmowę z biznesem. Pytamy działy, z jakich raportów faktycznie korzystają. Często okazuje się, że z 50 tworzonych w Power Query raportów, regularnie czytane są tylko 4. Wiedząc to, możemy skupić się na migracji tylko tych procesów, które zasilają te 4 raporty, zostawiając resztę do ewentualnego nadrobienia w przyszłości. Oszczędzamy dzięki temu tygodnie pracy na przenoszenie czegoś, co z perspektywy firmy nie ma już żadnej wartości.
Ostatnim etapem tej fazy jest wstępne zaplanowanie struktury w nowym miejscu. Skoro mamy dane z ERP (sprzedaż), z SQL Servera (historia klientów) i z Excela (budżety), w BigQuery nie wrzucimy ich do jednego worka. Planujemy podział na warstwy: warstwę surową (gdzie lądują dane 1:1 z plików), warstwę czyszczącą (gdzie zmieniamy typy i usuwamy błędy) oraz warstwę raportową (połączone i wyliczone widoki, gotowe do podpięcia pod dashboard). Mając taką mapę drogową, czyste pliki i odrzucone śmieci, jesteśmy gotowi na wejście do Google Cloud.
Faza 2: Konfiguracja Google Cloud Platform (GCP) krok po kroku
Wchodzimy na nowe terytorium. Dla osoby, która do tej pory pracowała głównie w ekosystemie lokalnego Excela i Windowsa, panel Google Cloud Platform (GCP) może wydać się początkowo onieśmielający. Pełno tu menu, zakładek, usług o dziwnie brzmiących nazwach. Bez obaw – nie musimy znać ich wszystkich. Skupimy się na wydeptaniu wąskiej ścieżki od logowania do uruchomienia BigQuery. Zaczynamy od wejścia na stronę console.cloud.google.com i zalogowania się naszym służbowym kontem Google.
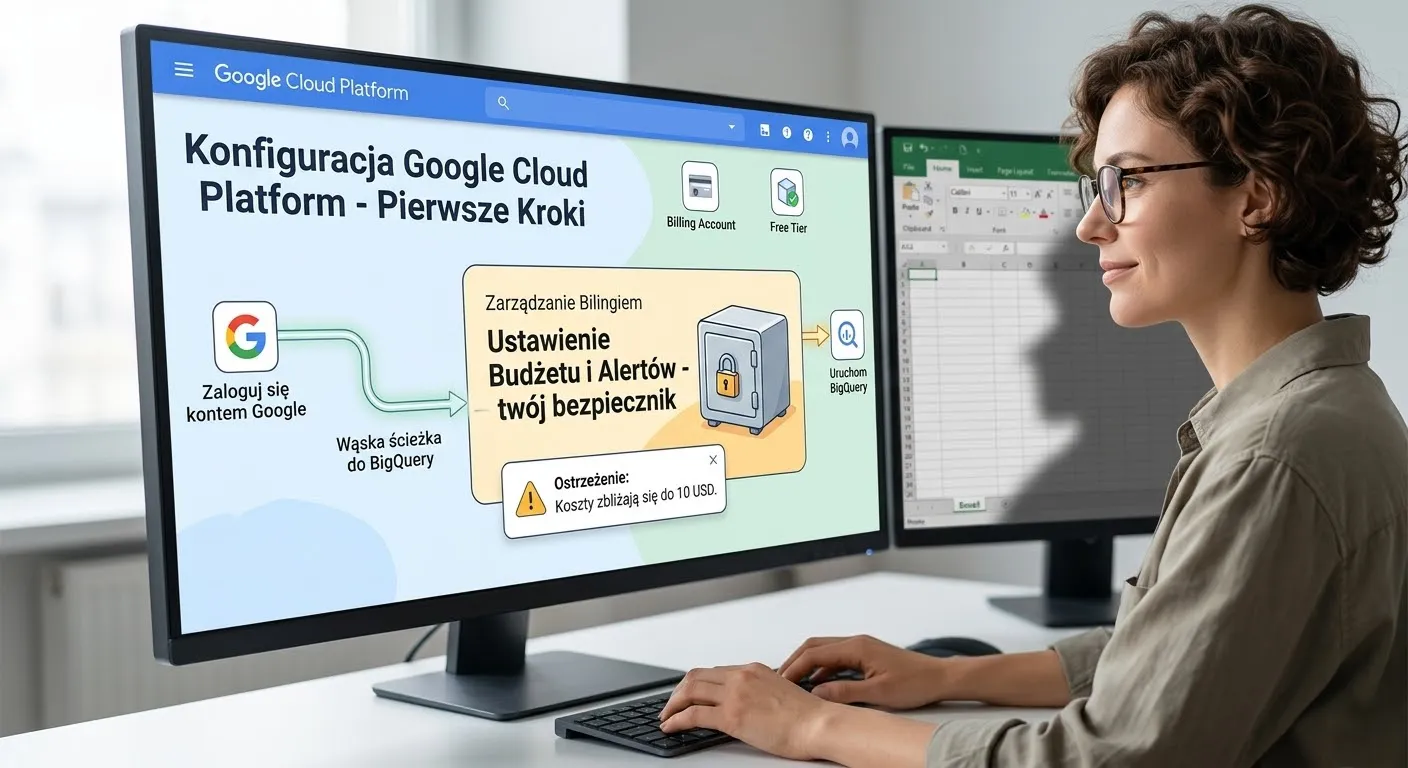
Pierwszym progiem, przez który musimy przejść, jest założenie konta bilingowego (Billing Account). Nawet jeśli planujemy korzystać z darmowego limitu (Free Tier, o którym powiemy później), Google musi mieć podpiętą kartę płatniczą lub umowę firmową, aby w ogóle pozwolić nam na tworzenie zasobów. To często moment stresujący dla początkujących, ale spokojnie – zrobimy to mądrze. Po podpięciu karty od razu ustalamy tzw. budżety i alerty (Budgets & alerts). Konfigurujemy powiadomienie, które wyśle nam maila, gdy koszty w danym miesiącu przekroczą np. 10 dolarów. To nasz bezpiecznik, który chroni nas przed nieprzyjemnymi niespodziankami.
Mając kwestie finansowe za sobą, tworzymy nasz pierwszy Projekt. W Google Cloud wszystko jest przypisane do projektu – to taki nadrzędny folder, który organizacyjnie spina nasze usługi, dane i użytkowników. Nadajemy mu sensowną nazwę, np. „hurtownia-danych-migracja”. Proces tworzenia trwa kilkanaście sekund. Gdy projekt jest gotowy, upewniamy się, że z listy rozwijanej na samej górze interfejsu mamy wybrany dokładnie ten nowo utworzony obszar roboczy.
Teraz musimy powiedzieć chmurze, jakich narzędzi będziemy używać. Domyślnie wiele usług jest wyłączonych, by nie zaśmiecać widoku. Przechodzimy do sekcji „APIs & Services”, wyszukujemy „BigQuery API” i klikamy „Enable” (Włącz). Od tego momentu BigQuery jest gotowe do pracy w naszym projekcie. Oprócz tego od razu włączamy „Google Cloud Storage API” – będzie nam to potrzebne do przetrzymywania naszych ciężkich plików CSV zanim trafią do bazy.
Przechodzimy do samego interfejsu BigQuery, wpisując jego nazwę w górną wyszukiwarkę. Otwiera się przed nami okno z eksploratorem po lewej stronie i miejscem do wpisywania zapytań SQL po prawej. Wygląda to trochę jak bardzo uproszczony, nowoczesny notatnik. Nasz projekt już tam widnieje. Klikamy na niego i wybieramy opcję „Create dataset” (Utwórz zbiór danych). Dataset w BigQuery to odpowiednik schematu (schema) w tradycyjnych bazach danych – grupuje tabele w logiczną całość.
Podczas tworzenia datasetu musimy podjąć jedną z kluczowych decyzji: wybór lokalizacji (Data location). Do wyboru mamy różne regiony (np. europe-west4, us-central1) oraz multi-regiony (np. EU, US). Z racji tego, że jesteśmy w Polsce i chcemy przestrzegać zasad RODO, wybieramy lokalizację europejską, np. region europe-central2 (Warszawa) lub po prostu EU. Ważne: raz wybranej lokalizacji datasetu nie da się łatwo zmienić, a wszystkie tabele wchodzące w jego skład, a także zapytania do nich kierowane, muszą znajdować się i być procesowane w tym samym regionie. Tworzymy na początek dwa datasety: raw_data (na surowe rzuty plików) oraz dwh_core (na nasze obrobione tabele analityczne).
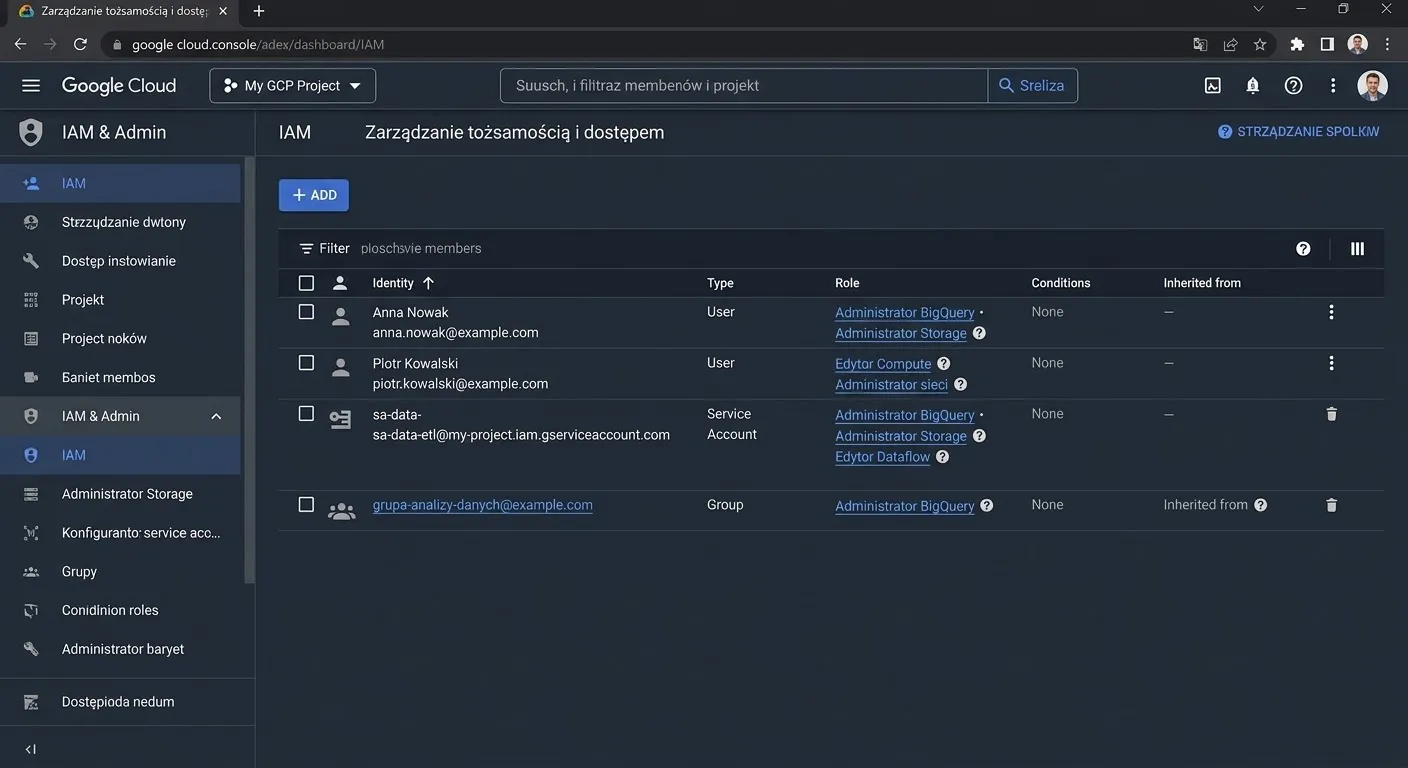
Na koniec tej fazy, musimy załatwić jeszcze jedną, prozaiczną, ale ważną rzecz: dostępy (IAM – Identity and Access Management). Skoro uciekliśmy z lokalnego Excela po to, by współpracować, musimy zaprosić kolegów z zespołu do projektu. W panelu IAM dodajemy adresy e-mail analityków i nadajemy im odpowiednie role. Zamiast dawać wszystkim pełnię władzy („Owner”), nadajemy im rolę „BigQuery Data Editor”, co pozwoli im tworzyć i modyfikować tabele, ale zablokuje możliwość przypadkowego usunięcia całego projektu. Środowisko jest czyste, bezpieczne i gotowe na przyjęcie pierwszych danych.
Faza 3: Migracja MS Excel i plików CSV do BigQuery. Najszybsze zwycięstwo
Przyszedł czas na konkrety – ładujemy nasze dane do chmury. Na pierwszy ogień idą mniejsze słowniki z Excela oraz paczki z plikami CSV z systemu ERP. Zaczniemy od małych rzeczy, by poczuć to „szybkie zwycięstwo”. Nasze słowniki Excelowe, po uprzednim posprzątaniu w Fazie 1, przenosimy do Google Sheets. Dlaczego? Ponieważ BigQuery posiada wbudowaną, genialną w swej prostocie integrację z Arkuszami Google. W BigQuery klikamy „Add Data” -> „External data source” i wklejamy link do naszego Google Sheet.
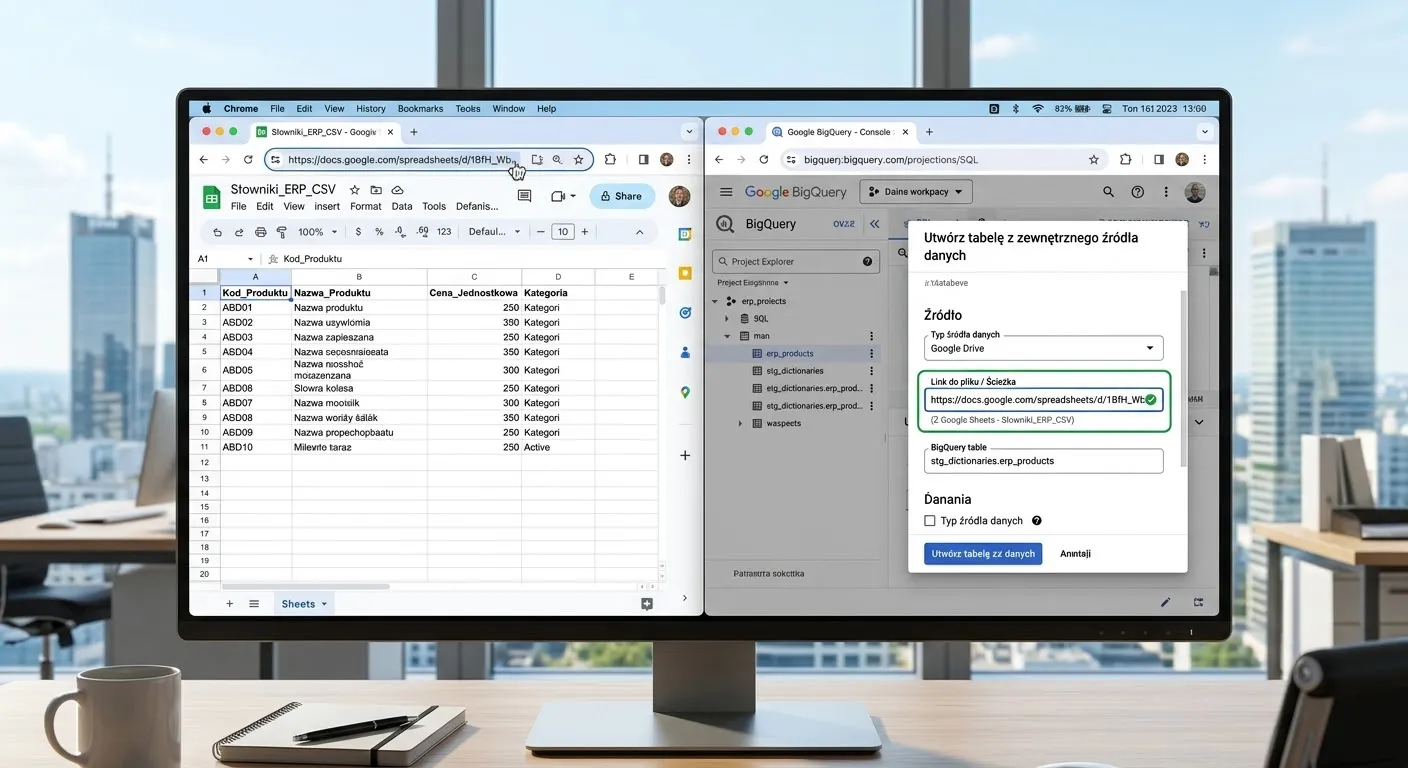
W ten sposób tworzymy Tabelę Zewnętrzną (External Table). Oznacza to, że BigQuery fizycznie nie kopiuje tych danych do siebie. Za każdym razem, gdy napiszemy zapytanie SQL do tej tabeli, BigQuery „w locie” odczyta aktualny stan Arkusza Google. To idealne rozwiązanie dla plików, które marketing czy HR musi regularnie aktualizować. Oni edytują arkusz w znany sobie sposób (w przeglądarce), a my w tej samej sekundzie mamy dostęp do najświeższych danych w hurtowni, bez żadnego przepinania kabli, odświeżania raportów czy błędów ścieżek. Problem braku dostępu do danych źródłowych wyparował.
Teraz zajmijmy się czymś grubszym – naszymi tygodniowymi zrzutami CSV od systemu ERP. Tabela Zewnętrzna z Google Sheets się nie sprawdzi (arkusze mają limity wierszy). Tutaj do gry wkracza Google Cloud Storage (GCS) – to taki chmurowy pendrive bez limitu pojemności. W panelu GCS tworzymy „Wiaderko” (Bucket) i po prostu przeciągamy nasze pliki CSV z lokalnego dysku do przeglądarki. Upload kilkuset megabajtów trwa chwilę (zależy tylko od szybkości naszego łącza). Gdy pliki leżą bezpiecznie w GCS, wracamy do BigQuery.
W BigQuery tworzymy nową tabelę z użyciem opcji „Create table from Google Cloud Storage”. Wskazujemy ścieżkę do naszych wgranych plików CSV (możemy użyć znaku gwiazdki *, np. dane_sap_*.csv, żeby BigQuery zaczytało od razu wszystkie pliki na raz do jednej tabeli!). Określamy separator, pomijamy pierwszy wiersz (nagłówki) i pozwalamy BigQuery na automatyczne wykrycie schematu (Auto-detect schema). Klikamy „Create” i dzieje się magia. Miliony wierszy w ułamku sekundy lądują w pełnoprawnej tabeli analitycznej.
Porozmawiajmy teraz o konkretach, czyli zestawieniu orientacyjnego czasu pracy i wygody. W naszej erze Power Query (PQ), co tydzień dostawaliśmy około 15 nowych plików CSV, z których każdy ważył po 50 MB. Sama próba otwarcia pliku raportowego w Excelu to 2-3 minuty. Kliknięcie „Odśwież wszystko” uruchamiało lawinę: procesor wskakiwał na 100%, wiatraki huczały, a my przez 15 do 30 minut nie mogliśmy nic zrobić na komputerze. Często po 20 minutach proces wywalał błąd braku pamięci (Out of Memory) albo informował, że ktoś zmienił nazwę jednego pliku i trzeba było poprawiać ścieżki i zaczynać od nowa. To była godzina czystej irytacji.
Z kolei po migracji do BigQuery (BQ), proces wygląda zgoła inaczej. Wgranie tych samych 15 plików do Cloud Storage metodą „przeciągnij i upuść” zajmuje około 2 minut w tle. Skrypt SQL, który ładuje te pliki, oczyszcza je i dołącza do głównej tabeli sprzedażowej działa przez… 3 do 5 sekund. Odpytanie tej bazy i wygenerowanie ostatecznego wyniku do analizy to kolejne 2 sekundy. Oszczędzamy niemal godzinę pracy z jednego procesu, zachowujemy pełną wydajność komputera, a wygoda rozwiązania polega na tym, że operacja uda się za każdym razem, bo infrastruktura nas nie ogranicza.
Dla plików, które są na tyle małe (np. do 100 MB w jednym pliku), BigQuery oferuje nawet przycisk „Upload”, pozwalający załadować CSV prosto z dysku komputera, omijając nawet Storage. My jednak wolimy trzymać pliki w GCS jako naszą bezpieczną kopię zapasową (backup warstwy surowej). Mając dane Excelowe wpięte na żywo z Sheetsów oraz ogromne pliki płaskie sprawnie zasilające główne tabele z GCS, odhaczyliśmy największe bolączki. Nasze „Szybkie Zwycięstwo” stało się faktem.

Faza 4: Wyzwanie – baza danych SQL i przenoszenie dużych zbiorów
Nasze CSV to był przedsmak. Prawdziwe wyzwanie czeka w piwnicy – tam, gdzie stoi zapomniany Microsoft SQL Server (lub jakakolwiek inna baza danych: Oracle, MySQL, Postgres), zawierający miliony rekordów historii klientów i konfiguracji produktowych z ostatnich 10 lat. Tego nie wyeksportujemy ręcznie do pojedynczego pliku CSV i nie przeciągniemy myszką. Próba wykonania „Zapisz jako CSV” na tabeli z 50 milionami wierszy w SQL Server Management Studio (SSMS) prawdopodobnie zawiesiłaby ten serwer i zablokowała pracę innych aplikacji. Musimy zadziałać sprytniej.
Pierwszym podejściem, często stosowanym przy tańszych i jednorazowych migracjach, jest dzielenie eksportu. Zamiast jednej gigantycznej paczki, piszemy na MS SQL zapytanie, które zrzuci nam dane do płaskich plików tekstowych z podziałem na lata. Otrzymamy plik „klienci_2015.txt”, „klienci_2016.txt” itd. Do takiego zrzutu możemy wykorzystać narzędzie bcp (Bulk Copy Program), wbudowane w MS SQL, które jest niesamowicie szybkie w wypluwaniu danych do formatów płaskich bez obciążania interfejsu graficznego. Następnie te pliki możemy skompresować, np. używając kompresji ZIP, wypchnąć do Cloud Storage i wgrać do BQ, jak w Fazie 3.
To jednak podejście mocno chałupnicze. Zrobimy to raz, przy pierwszej migracji. A co, jeśli w tym SQL Serverze dane wciąż żyją i są dopisywane codziennie? Potrzebujemy potężniejszego mostu. Wchodzimy w świat narzędzi ETL (Extract, Transform, Load) i ELT (Extract, Load, Transform). Z pomocą mogą nam przyjść gotowe, zewnętrzne konektory, takie jak Fivetran, Airbyte czy Stitch. Wymagają one podania adresu IP naszego serwera SQL (który musi być widoczny w sieci) oraz danych logowania. Narzędzia te same „wysysają” dane ze źródła, mapują typy i wrzucają je do BigQuery. To najwygodniejsza metoda, ale wiąże się z opłatami za licencje tych narzędzi.
Jeśli chcemy pozostać w pełni w ekosystemie Google, nie chcemy dodatkowych kosztów i mamy w zespole programistów Pythona lub Javy, możemy użyć usługi Google Cloud Dataflow. Tworzymy potok przesyłowy (pipeline) w Apache Beam, który połączy się przez JDBC do naszego starego serwera MS SQL, pobierze wiersze w strumieniu, po drodze ewentualnie zmieni format dat czy usunie znaki specjalne, i zapisze je do tabel w BQ. Dataflow skaluje się automatycznie – jeśli tabela w SQL ma gigabajty, powoła do życia kilka maszyn, by przetworzyć ten eksport równolegle, drastycznie ucinając czas oczekiwania.
Inną interesującą alternatywą, prosto od Google, jest usługa Datastream. Datastream potrafi wpiąć się w mechanizmy replikacji bazy danych (np. logi CDC – Change Data Capture). Nie obciąża to źródłowej bazy MS SQL ciągłymi zapytaniami SELECT. Narzędzie nasłuchuje zmian – jeśli ktoś lokalnie doda nowego klienta lub usunie zamówienie, Datastream chwyta ten pojedynczy fakt z logu i przesyła ten mikroskopijny pakiet bezpośrednio do BigQuery w czasie bliskim rzeczywistemu (near real-time). Baza źródłowa i BQ stają się zsynchronizowanymi lustrami.
Podczas migracji baz relacyjnych do BigQuery musimy uważać na typy danych. Tradycyjny SQL Server ma precyzyjne typy jak VARCHAR(50), NVARCHAR, DATETIME2. W BigQuery panuje większa swoboda. Tekst to po prostu STRING (może pomieścić 2 MB znaków). Daty stają się typami DATE lub TIMESTAMP. Nasze skrypty eksportujące lub narzędzia ETL muszą dbać o rygorystyczne i poprawne zmapowanie tych typów po drodze, abyśmy po załadowaniu danych w BigQuery nie odkryli, że nasze sumy sprzedażowe są traktowane jako tekst i nie da się ich zsumować w agregacji. Przenoszenie danych to precyzyjna operacja na otwartym sercu.


Faza 5: Modelowanie danych w BigQuery. Budowa jednej wersji prawdy
Dane wylądowały w chmurze. Mamy historyczne tabele klientów z MS SQL, ciężkie logi transakcji z CSV i słowniki celów marketingowych z Excela w Google Sheets. Każde źródło żyje w swoim datasetcie raw_data. Sukces? Jeszcze nie. Jeśli na tym etapie wpuścimy użytkowników biznesowych, uciekną z krzykiem. Kolumny mają nieczytelne nazwy, w danych nadal jest pełno brudu, a poszczególne tabele w żaden sposób ze sobą nie rozmawiają. Nadszedł czas na modelowanie – serce pracy analityka w BigQuery. Używamy do tego starego, dobrego SQL-a.
BigQuery używa standardowego dialektu SQL (Standard SQL, zgodnego z ANSI), co jest ogromnym plusem, bo składnia jest niemal identyczna jak w PostgreSQL czy MS SQL. Naszym pierwszym zadaniem jest utworzenie „Widoków” (Views). Widok to wirtualna tabela, która jest wynikiem działania zapytania SQL, wykonywanego w momencie odpytania. Piszemy więc zapytanie:
SELECT nazwa_produktu, CAST(kwota_sprzedazy AS FLOAT64) FROM raw_data.sap_sprzedaz WHERE status_zamowienia = 'zrealizowane’.
To zapytanie w locie zmienia format kwoty z nieszczęsnego tekstu na liczbę zmiennoprzecinkową i odfiltrowuje błędy. Zapisujemy to jako widok clean_sprzedaz.
Teraz musimy połączyć dane ze sobą. Marketing w Excelu posługuje się tylko ID kampanii, a sprzedaż uważa ID produktu za klucz główny. Musimy napisać zapytanie, wykorzystujące polecenia JOIN, aby połączyć wyczyszczoną sprzedaż z tabelą wymiarów od marketingu. Do tego używamy potężnych funkcji dostępnych w BQ. Jeżeli okaże się, że stringi z ID różnią się wielkością liter lub wiodącymi zerami, stosujemy na miejscu operacje takie jak UPPER(), TRIM() czy funkcje formatujące tekst, by klucze wreszcie się zgadzały. W Power Query podobne operacje zjadłyby połowę dostępnej pamięci – BQ robi to, przeglądając miliony wierszy w dwie sekundy.
W BigQuery, inaczej niż w tradycyjnych bazach, mamy genialne rozwiązanie na rozbudowane, wulgarne wręcz zapytania, które trudno zrozumieć na pierwszy rzut oka – klauzulę WITH (Common Table Expressions – CTE). Zamiast pisać zagnieżdżone podzapytania w podzapytaniach, układamy logikę krokowo od góry do dołu.
Zaczynamy:
WITH sprzedaz_2023 AS (…),
Następnie:
WITH klienci_premium AS (…),
aż na końcu piszemy proste:
SELECT * FROM sprzedaz_2023 JOIN klienci_premium….
Taki kod w BQ czyta się jak książkę, a edycja pojedynczego „kroku” przypomina edytowanie kroków w panelu bocznym Power Query, z tą różnicą, że mamy tu totalną kontrolę nad wykonaniem.
Ważnym etapem modelowania jest zmiana myślenia o architekturze. W starych bazach relacyjnych (jak MS SQL) zawsze dążyliśmy do tzw. normalizacji bazy – dzieliliśmy dane na setki małych słowników, żeby oszczędzać miejsce. W BigQuery przestrzeń dyskowa jest śmiesznie tania, natomiast moc obliczeniowa na łączenie wielu tabel (JOIN) kosztuje ułamki czasu i zasobów zapytania. Dlatego dążymy do denormalizacji. Zamiast widoku, który robi siedem joinów przy każdym odświeżeniu raportu, używamy zapytań DDL (CREATE OR REPLACE TABLE) do stworzenia jednej, gigantycznej, szerokiej na 100 kolumn tabeli „Złotej_Warstwy”, gotowej do wyplucia wyników natychmiastowo. Biznes dostaje w tej postaci płaską, wymodelowaną strukturę bez martwienia się o powiązania z tyłu.

Ostatecznym wynikiem Fazy 5 jest wykreowanie datasetu, który nazwaliśmy dwh_core (Data Warehouse Core), w którym lądują starannie spreparowane i zoptymalizowane pod raporty Tabela Faktów i Wymiarów. W tym miejscu błędy ortograficzne w kategoriach klientów zostały załatane konstrukcją CASE WHEN, kwoty walutowe ustandaryzowane do PLN, a daty przyjęły przyjazny format YYYY-MM-DD. Mamy zaufane jedno źródło prawdy. Teraz nikt w firmie nie może przyjść na spotkanie z dwiema różnymi wersjami przychodów z zeszłego miesiąca. Jest tylko to, co leży w naszej wymodelowanej tabeli.
Faza 6: Utrzymanie i automatyzacja. Niech to działa samo
Migracja została zakończona sukcesem. Uff! Ale zaraz… czy od teraz do końca moich dni na etacie muszę wchodzić w poniedziałek rano do konsoli Google Cloud, wrzucać CSV do GCS i ręcznie uruchamiać skrypty SQL, by odświeżyć tabelę główną? Oczywiście, że nie. Cały urok pracy inżynieryjnej i analitycznej w chmurze polega na tym, że najtrudniej robi się coś za pierwszym razem. Resztę życia proces ma toczyć się w tle, a my zrobimy sobie zasłużoną kawę, analizując już gotowe wyniki, a nie pracując jako ręczni przeklepywacze danych.
Najprostszą formą automatyzacji w BigQuery są „Scheduled Queries” (Zapytania harmonogramowane). To dosłownie wbudowany w interfejs zegarek. Jeśli nasza „Złota Warstwa” (denormalizowana, szeroka tabela, o której wspominaliśmy w Fazie 5) opiera się o kilka widoków pobierających dane na żywo, musimy ją co jakiś czas fizycznie nadpisać nowymi danymi. Piszemy więc skrypt SQL aktualizujący (np. MERGE, albo proste usuń i wstaw TRUNCATE / INSERT) i w panelu ustawiamy, aby Google odpalało ten skrypt w każdą niedzielę o 3:00 w nocy. Zanim zaczniemy pracę w poniedziałek, silniki Google zaktualizują tabele, a my dostaniemy mailem raport z zielonym znaczkiem „Success”.

Co jednak w przypadku naszych plików CSV, które ktoś musi „przenieść” z serwera do Google Cloud Storage? Tu wkracza prosta aplikacja np. w języku Python. Możemy napisać króciutki kod używając biblioteki google-cloud-storage. Kod loguje się do naszego lokalnego serwera, łapie wszystkie pliki o zadanej nazwie i wypycha do chmurowego Bucket-a. Taki skrypt możemy odpalić z harmonogramu zadań systemu Windows w naszej firmie. Nie wymaga to zaawansowanych systemów. Po prostu automatycznie przesuwa pliki, gdy tylko się pojawią.
Jeśli chcemy zbudować profesjonalną orkiestrację procesów bez kodowania lokalnego serwera, zaprzyjaźniamy się z narzędziem Google Cloud Composer (opartym na Apache Airflow). Composer to nasz chmurowy dyrygent. Możemy mu w łatwy sposób rozpisać mapę zależności (DAG).
Na przykład:
Krok 1 – sprawdź, czy w Cloud Storage pojawił się nowy plik CSV.
Krok 2 – jeśli tak, wymuś jego import do tabeli raw_data.
Krok 3 – po udanym imporcie, uruchom zapytanie modelujące dane (nasz skrypt z Fazy 5).
Krok 4 – wyślij powiadomienie na komunikator (np. Slack) do całego zespołu: „Nowe dane załadowane, zapraszamy do analizy”. Jeśli na jakimś etapie pojawi się błąd, proces zatrzymuje się, a my dostajemy szczegółowe logi zdarzenia.
Dzięki automatyzacji opartej o mechanizmy „serverless”, uniknęliśmy najgorszego koszmaru administratorów. Dawniej odświeżanie ciężkich procesów w nocy potrafiło zawiesić serwer na wiele godzin, a na rano nikt nie miał raportów. W BigQuery w chmurze nie istnieje pojęcie „braku pamięci”, „zawieszenia” czy „zbyt wolnego dysku”. Google pod maską przydziela kilkaset rdzeni procesora, przelicza nasz harmonogram i znika. My z kolei zyskujemy poczucie kontroli nad stabilnością raportowania, którego w Power Query po prostu technicznie nie dało się zagwarantować. Nareszcie dane same przychodzą do nas, a nie my chodzimy po dane.
Koszty i optymalizacja: Jak nie zbankrutować, używając BigQuery

Przejście z Power Query na Excelu do płatnej chmury zawsze wzbudza dreszczyk przerażenia u księgowości. Przecież chmura potrafi wygenerować monstrualne rachunki za błąd ludzki, prawda? Tak, potrafi, jeśli wejdziemy do niej po omacku. Cennik BigQuery opiera się na dwóch oddzielnych filarach. Pierwszy z nich to koszt składowania danych (Storage). Płacimy miesięcznie za każdy gigabajt przestrzeni, który zajmują nasze tabele. Drugi filar to koszt przetwarzania (Compute), czyli „rachunek za odpytywanie”. Płacimy za ilość gigabajtów lub terabajtów, przez które BigQuery musiało „przeskanować”, aby odpowiedzieć na nasze zapytanie SQL. Zrozumienie tego ratuje portfele.
Zacznijmy od dobrych wiadomości. Google oferuje limit darmowy (Free Tier). Co miesiąc otrzymujemy 10 GB darmowego przechowywania przestrzeni dyskowej oraz – uwaga – aż 1 Terabajt (1000 GB) darmowego procesowania zapytań! Wróćmy do naszych zrzutów z plików CSV. Nasze pliki ważyły po kilkadziesiąt megabajtów w Excelu. Nawet po kilkunastu miesiącach dane w naszym „małym” polskim oddziale z trudem osiągną granicę kilkunastu gigabajtów. Prawdopodobnie przy sprawnej kompresji, całe nasze archiwum i tabele produkcyjne przez kilka lat będą nas kosztować od kilku do maksymalnie kilkunastu złotych miesięcznie z tytułu Storage.
Schody mogą pojawić się przy zapytaniach (Compute). W BigQuery używamy bazy kolumnowej. Oznacza to najprostszą zasadę życia i śmierci: pod żadnym pozorem nigdy, przenigdy nie pisz w środowisku produkcyjnym zapytania:
SELECT * FROM bardzo_duza_tabela.
Dlaczego? Gwiazdka zmusza silnik do przeskanowania absolutnie wszystkich kolumn w tabeli od góry do dołu. Jeśli tabela zajmuje na dysku 500 GB, jedno kliknięcie pochłonie połowę darmowego limitu z całego miesiąca.
Odpytuj zawsze tylko o te kolumny, których faktycznie potrzebujesz:
SELECT ID_Klienta, Kwota FROM …
Takie zapytanie zredukuje zeskanowany obrót z 500 GB do np. 10 GB.
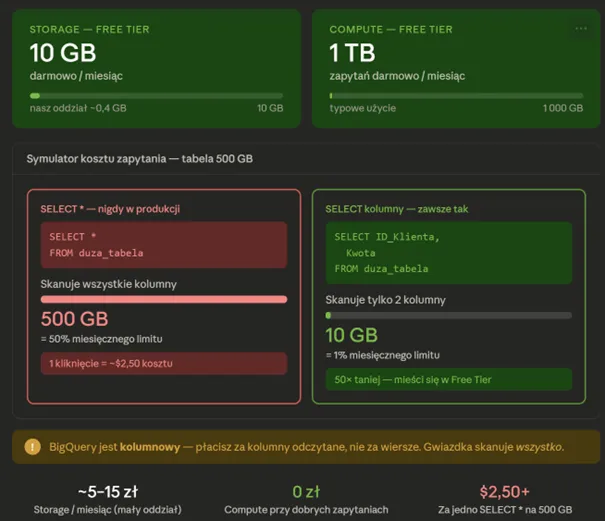
Drugą złotą zasadą optymalizacji finansowej jest Partycjonowanie tabel (Partitioning). Zakładając tabelę z historią sprzedaży, dodajemy mechanizm partycji np. po dacie sprzedaży. Co to zmienia? W wielkim skrócie: tnie naszą wielką, szafopodobną tabelę na małe szufladki odpowiadające poszczególnym dniom lub miesiącom. Kiedy analityk napisze zapytanie: SELECT … WHERE data = '2023-11-01′, BigQuery otworzy tylko jedną „szufladkę” z tym konkretnym dniem i pobierze z niej drobne centy za procesowanie. Bez partycjonowania otworzyłoby całą szafę z ośmiu lat, skanując wszystko po kolei.
Wspomniane wcześniej limity na poziomie konta (Budgets) również stoją na straży bezpieczeństwa. W GCP możesz nałożyć tzw. „Custom Quota” dla każdego użytkownika. Możesz zarządzić, że dany stażysta w dziale może maksymalnie przeskanować 50 GB danych dziennie. Po przekroczeniu tego limitu jego kolejne zapytania zostaną zablokowane z błędem, aż do resetu licznika o północy. To fantastyczne narzędzie wychowawcze, które uczy analityków pisać czysty, przemyślany i selektywny kod SQL, zamiast „strzelać na oślep” w wielkie zbiory danych na koszt pracodawcy. Mądrze ustawione BQ potrafi być tańsze od utrzymania tradycyjnego serwera z bazą pod biurkiem.
Podsumowanie i kolejne kroki. (A co powiesz na Looker Studio?)

Dotarliśmy do brzegu. Otworzyliśmy firmowe szafy, wyrzuciliśmy niepotrzebne pliki w Fazie audytu i utworzyliśmy bezpieczny dom w Google Cloud Platform. Porzuciliśmy ociężałe Power Query na rzecz nieograniczonych wiader w Cloud Storage. Podpięliśmy najcięższą bazę Microsoft SQL do najsilniejszych silników GCP. Uporządkowaliśmy ten chaos używając zwinnego języka SQL i powierzyliśmy aktualizacje harmonogramom i skryptom. Co najważniejsze, nasze portfele wyszły z tego bez szwanku – korzystamy z darmowych rozwiązań pod pełną kontrolą, a kiedy darmowe środki się skończą – wdrożyliśmy system pełnej kontroli nad kosztami chmury.
Migracja była ciężką drogą, która drastycznie poprawiła kulturę pracy w całej organizacji.
Jakie są te kluczowe zalety? Zrezygnowaliśmy z awaryjnego systemu lokalnych, krucho zdefiniowanych ścieżek „C:/Users/…”. Ktoś usunie katalog na pulpicie? Baza tego nie poczuje, bo wszystko odbywa się poza maszyną użytkownika. Odzyskaliśmy utracony czas – nasze „ciężkie” poniedziałki ze sprawdzaniem, „kto teraz zawiesił plik”, zamieniły się w automatyczny dzwonek powiadomienia na czacie, że wszystkie dane przygotowano w pięć sekund. Analitycy mogą zająć się wyszukiwaniem korelacji i trendów, zamiast zabawą w konserwatorów od ścieżek w Excelu i naprawiaczy błędów, np. braku pamięci.
Dane zostały ostatecznie zdemokratyzowane. Nasze Złote Warstwy danych opowiadają każdemu w firmie dokładnie taką samą historię o zyskach. Nie musimy wysyłać nikomu plików Excel z wynikami, wystarczy wydać dostęp do tabeli. Infrastruktura Google zajęła się również pełnym bezpieczeństwem – nasze dane są szyfrowane i kopiowane przez najbardziej zaawansowane mechanizmy zabezpieczeń na rynku IT. Wyjście z zamkniętej, tradycyjnej serwerowni sprawiło, że bez inwestycji wielu tysięcy złotych staliśmy się cyfrowo dojrzalszą i sprawniejszą firmą.
Sama baza i czyste tabele to jednak dopiero szkielet cyfrowej architektury. Suche rzędy cyferek nie przyniosą prezesowi rewelacyjnych wniosków. Naszym oczywistym kolejnym krokiem i wisienką na torcie powinna być warstwa wizualizacyjna. Skoro jesteśmy już głęboko w środowisku Google, doskonałym narzędziem, które natywnie komunikuje się z naszymi zbiorami i modelami w BigQuery jest Looker Studio (wcześniej Data Studio). Jest to potężne, w pełni darmowe narzędzie BI (Business Intelligence) do wyklikiwania interaktywnych, eleganckich dashboardów, wykresów i raportów.
Wystarczy wejść do Looker Studio, założyć nowy raport i wybrać opcję połączenia z Google BigQuery. System sam połączy się z naszym projektem „hurtownia-danych-migracja”. Tam znajdujemy naszą wyczyszczoną, złotą tabelę z wynikami. Po chwili wykresy słupkowe, mapy i trendy wskaźników same malują się na ekranie. Odświeżają się w mgnieniu oka – w końcu silnik, który odpowiada na zapytania klikających po wykresie menedżerów to ten sam silnik BigQuery. Czas zacząć wizualizować nasz nowy, uporządkowany chmurowy sukces. Prawda, że warto było przejść tę drogę?
Potrzebujesz wsparcia? Zróbmy to razem!
Przejście z lokalnych, często chaotycznych plików i powolnych odświeżeń do nowoczesnej hurtowni danych to ogromny krok dla każdej firmy. Jeśli po lekturze tego artykułu czujesz, że Twój biznes potrzebuje takiej zmiany, ale nie chcesz przechodzić przez to w pojedynkę – zespół Imperium Szkoleniowe jest do Twojej dyspozycji.
Pomagamy firmom na każdym etapie pracy z danymi:
- Przeprowadzimy bezpieczną migrację: Bierzemy na siebie techniczny ciężar przeniesienia Twoich danych. Niezależnie od tego, czy zmagasz się z bałaganem w plikach CSV, ograniczeniami systemów ERP, czy starymi bazami SQL – ułożymy z tego zautomatyzowany i wydajny proces.
- Nauczymy Cię korzystać z BigQuery: Nie zostawiamy Cię z „czarną skrzynką”. Prowadzimy praktyczne szkolenia, dzięki którym Ty i Twój zespół nauczycie się samodzielnie pracować w środowisku Google Cloud i wyciągać z niego to, co najważniejsze.
- Zbudujemy gotowe raporty: Kiedy dane będą już na swoim miejscu, przekujemy je w wiedzę. Tworzymy przejrzyste, automatycznie odświeżane dashboardy (np. w Looker Studio), które od razu wspierają podejmowanie decyzji biznesowych.
Zostaw walkę z niedziałającymi ścieżkami plików za sobą. Skontaktuj się z nami, a pomożemy Ci zbudować środowisko analityczne, które po prostu działa.

Git dla analityków danych – dlaczego Excel nie wystarcza do kontroli wersji?

Czy BigQuery to dobre rozwiązanie analityczne dla średniej firmy?

SQL w BigQuery – czym różni się od klasycznego SQL?

Ile kosztuje BigQuery w praktyce? Przykładowe wyliczenia
