
Czy BigQuery to dobre rozwiązanie analityczne dla średniej firmy?
BigQuery
Analityka danych
Spis treści:
- Wstęp
- Dlaczego klasyczna analityka zaczyna być problemem wraz ze wzrostem firmy?
- Jak działa BigQuery i dlaczego różni się od klasycznych baz danych?
- Kiedy BigQuery rzeczywiście daje przewagę średniej firmie?
- Jakie są największe pułapki wdrożenia BigQuery?
- BigQuery + Power BI — bardzo mocne połączenie czy problematyczny duet?
- Czy BigQuery jest opłacalny dla średniej firmy?
- Podsumowanie
Wstęp
W świecie danych bardzo łatwo wpaść w dwie skrajności. Z jednej strony wiele średnich firm nadal próbuje rozwijać analitykę na arkuszach Excel, lokalnych bazach SQL i pojedynczych raportach Power BI aktualizowanych ręcznie raz dziennie. Z drugiej strony coraz częściej pojawia się pokusa wdrożenia rozbudowanych platform data engineeringowych rodem z korporacji technologicznych, które kosztują więcej niż realnie są warte dla organizacji zatrudniającej 100–500 osób.
W praktyce największym problemem średnich firm nie jest dziś brak danych. Problemem jest raczej brak spójności, wydajności i możliwości skalowania analiz. Dane są rozsiane pomiędzy ERP, CRM, e-commerce, marketingiem, plikami Excel i systemami księgowymi. Raporty działają wolno, użytkownicy nie ufają wynikom, a dział analityczny coraz więcej czasu poświęca na „gaszenie pożarów” niż realne wspieranie biznesu.
W tym miejscu coraz częściej pojawia się Google BigQuery — hurtownia danych działająca w modelu serverless, będąca częścią ekosystemu Google Cloud. Jeszcze kilka lat temu rozwiązanie to kojarzyło się głównie z gigantycznymi zbiorami danych i firmami technologicznymi operującymi na miliardach rekordów. Dzisiaj sytuacja wygląda zupełnie inaczej. BigQuery coraz częściej trafia również do średnich organizacji, które potrzebują nowoczesnej analityki bez budowania kosztownej infrastruktury on-premise.
Pojawia się jednak kluczowe pytanie: czy BigQuery rzeczywiście ma sens dla średniej firmy, czy jest po prostu kolejnym modnym rozwiązaniem technologicznym?

Dlaczego klasyczna analityka zaczyna być problemem wraz ze wzrostem firmy?
W początkowej fazie działalności większość organizacji radzi sobie całkiem dobrze z prostą architekturą danych. Kilka raportów w Excelu, lokalna baza SQL, może prosty dashboard w Power BI — i biznes działa. Problem pojawia się wtedy, gdy firma zaczyna rosnąć.
Nagle okazuje się, że:
- dane pochodzą z kilkunastu różnych systemów,
- raporty liczą się po kilka minut,
- każda zmiana w modelu danych powoduje problemy,
- analitycy tworzą dziesiątki kopii tych samych tabel,
- pojawiają się konflikty dotyczące „jednej wersji prawdy”.
To dokładnie ten moment, o którym często mówi się przy projektowaniu modeli danych i architektury raportowej. Źle zaprojektowany model na początku projektu bardzo szybko zaczyna generować problemy wydajnościowe i organizacyjne.
W praktyce wiele średnich firm funkcjonuje dziś w architekturze przypominającej „patchwork”. Dane są kopiowane pomiędzy systemami, Power Query wykonuje coraz cięższe transformacje, a raporty Power BI działają w trybie importu, ponieważ DirectQuery okazuje się zbyt wolny lub ograniczony funkcjonalnie. Problem ten bardzo dobrze widać przy pracy z dużymi zbiorami danych i różnymi trybami pobierania danych w Power BI.
To właśnie tutaj BigQuery zaczyna mieć sens.
Nie dlatego, że jest „modny”. Dlatego, że rozwiązuje kilka fundamentalnych problemów:
- centralizuje dane,
- oddziela warstwę analityczną od raportowej,
- pozwala skalować analitykę bez rozbudowy infrastruktury,
- eliminuje wiele problemów wydajnościowych.
Kluczowe jest jednak zrozumienie jednej rzeczy: BigQuery nie jest magicznym rozwiązaniem, które automatycznie naprawi chaos danych. Jeżeli firma ma źle zaprojektowane procesy raportowe, niespójne definicje KPI i brak governance danych, sama migracja do chmury niewiele pomoże.
Jak działa BigQuery i dlaczego różni się od klasycznych baz danych?
Największą różnicą pomiędzy BigQuery a tradycyjnymi rozwiązaniami SQL jest architektura serverless. W praktyce oznacza to, że firma nie zarządza serwerami, klastrami ani skalowaniem infrastruktury. Google odpowiada za całą warstwę techniczną.
Dla średniej firmy jest to ogromna zmiana organizacyjna.
W klasycznym środowisku analitycznym często trzeba:
- utrzymywać serwery bazodanowe,
- planować pojemność infrastruktury,
- monitorować wydajność,
- rozwiązywać problemy związane z przeciążeniem.
BigQuery eliminuje znaczną część tych obowiązków. Firma płaci głównie za:
- przechowywanie danych,
- wykonane zapytania,
- dodatkowe usługi integracyjne.
To podejście bardzo dobrze wpisuje się w nowoczesny model analityki danych, w którym infrastruktura ma być elastyczna i skalowalna.
Co istotne, BigQuery bardzo dobrze współpracuje z językiem SQL. A mimo ogromnego rozwoju narzędzi no-code i BI, SQL nadal pozostaje fundamentalnym językiem analityki danych.
To niezwykle ważne, ponieważ wiele firm błędnie zakłada, że nowoczesna analityka oznacza całkowite odejście od SQL-a. Tymczasem nawet najbardziej zaawansowane narzędzia BI „pod spodem” generują zapytania SQL.
BigQuery bardzo dobrze wykorzystuje tę zależność. Dzięki temu:
- analitycy mogą pisać własne zapytania,
- Power BI może działać na gotowych agregacjach,
- transformacje danych można wykonywać bliżej źródła,
- raporty są znacznie wydajniejsze.
W praktyce oznacza to, że część logiki biznesowej warto przenieść z Power BI lub Excela bezpośrednio do warstwy hurtowni danych.
To podejście daje kilka korzyści jednocześnie:
- uproszczenie modeli raportowych,
- poprawę wydajności dashboardów,
- łatwiejsze utrzymanie logiki biznesowej,
- większą kontrolę nad jakością danych.
Kiedy BigQuery rzeczywiście daje przewagę średniej firmie?
To bardzo ważne pytanie, ponieważ nie każda organizacja potrzebuje hurtowni danych klasy BigQuery.
W praktyce największe korzyści pojawiają się wtedy, gdy firma zaczyna doświadczać przynajmniej kilku z poniższych problemów:
- raporty działają coraz wolniej,
- dane pochodzą z wielu systemów,
- analityka wymaga dużych wolumenów danych,
- Power BI zaczyna mieć problemy wydajnościowe,
- pojawia się potrzeba analityki near real-time,
- wiele zespołów korzysta z tych samych danych,
- firma rozwija e-commerce lub marketing performance,
- rośnie liczba integracji API i danych zdarzeniowych.
Szczególnie dobrze widać to w organizacjach rozwijających sprzedaż online. Dane z Google Analytics 4, systemów reklamowych, CRM i ERP bardzo szybko zaczynają tworzyć środowisko, którego Excel oraz lokalne raporty przestają obsługiwać wydajnie.
Dobrym przykładem może być średniej wielkości firma e-commerce działająca w kilku krajach Europy.
Początkowo raportowanie opierało się na:
- eksportach CSV,
- lokalnym SQL Serverze,
- Power BI Import Mode,
- ręcznych transformacjach Power Query.
Przy kilkunastu milionach rekordów miesięcznie raporty zaczęły działać bardzo wolno. Dodatkowo każda zmiana logiki biznesowej wymagała przebudowy wielu modeli danych.
Po migracji do BigQuery firma:
- scentralizowała dane marketingowe i sprzedażowe,
- przeniosła transformacje do SQL,
- ograniczyła obciążenie Power BI,
- skróciła czas odświeżania raportów z 40 minut do kilku minut.
Co ciekawe, największą korzyścią nie była sama wydajność. Największą zmianą okazało się uporządkowanie architektury danych i wyeliminowanie wielu lokalnych „obejść”, które wcześniej budowali analitycy.
To bardzo częsty efekt wdrożeń hurtowni danych.

Jakie są największe pułapki wdrożenia BigQuery?
Tutaj pojawia się najważniejszy aspekt całego tematu. BigQuery może być świetnym rozwiązaniem, ale bardzo łatwo wdrożyć go źle.
Najczęstszy błąd średnich firm polega na tym, że traktują hurtownię danych jak „większy dysk do raportów”. W efekcie do BigQuery trafiają chaotyczne dane, bez governance, bez warstwy semantycznej i bez standardów modelowania.
To prowadzi do sytuacji, w której firma płaci za nowoczesną technologię, ale nadal pracuje na nieuporządkowanych danych.
Drugi bardzo częsty problem to brak świadomości kosztów zapytań.
BigQuery działa w modelu pay-per-query, co oznacza, że źle napisane zapytania mogą generować niepotrzebne koszty. Szczególnie problematyczne bywają:
- skany pełnych tabel,
- nieoptymalne JOIN-y,
- brak partycjonowania,
- niekontrolowane DirectQuery z Power BI.
W praktyce oznacza to, że kompetencje SQL nadal są bardzo ważne. Dobrze napisane zapytanie może kosztować kilka groszy. Źle napisane — wielokrotnie więcej.
Trzecia pułapka to próba budowania „korporacyjnej architektury” w średniej firmie.
Wiele organizacji wdraża:
- Data Lake,
- skomplikowane pipeline’y,
- rozbudowane warstwy ETL,
- dziesiątki narzędzi orkiestracyjnych,
mimo że ich realne potrzeby są znacznie prostsze.
Efekt? Projekt staje się kosztowny, trudny w utrzymaniu i przestaje być elastyczny.
Średnia firma potrzebuje przede wszystkim:
- prostoty,
- skalowalności,
- szybkości wdrażania zmian,
- łatwego utrzymania.
I właśnie tutaj BigQuery potrafi być bardzo skuteczne — pod warunkiem rozsądnego podejścia architektonicznego.

BigQuery + Power BI — bardzo mocne połączenie czy problematyczny duet?
To jeden z najciekawszych scenariuszy dla średnich firm, ponieważ wiele organizacji nie chce rezygnować z Power BI jako warstwy raportowej.
I słusznie.
Power BI nadal pozostaje bardzo mocnym narzędziem wizualizacyjnym i analitycznym, szczególnie gdy raporty są dobrze zaprojektowane oraz zgodne z zasadami czytelnej wizualizacji danych.
Problem polega na tym, że wiele firm próbuje wykonywać całą logikę analityczną bezpośrednio w Power BI:
- ciężkie transformacje Power Query,
- skomplikowane miary DAX,
- ogromne modele importowe,
- wielopoziomowe relacje.
W pewnym momencie taki model zaczyna być trudny do utrzymania. Właśnie dlatego coraz częściej stosuje się podejście:
BigQuery = warstwa danych
Power BI = warstwa wizualizacji
To bardzo rozsądna architektura.
BigQuery odpowiada wtedy za:
- agregacje,
- transformacje,
- czyszczenie danych,
- modelowanie logiczne,
- integrację źródeł.
Power BI skupia się głównie na:
- dashboardach,
- KPI,
- interaktywności,
- analizie biznesowej,
- storytellingu danych.
To podejście znacząco poprawia wydajność i upraszcza modele raportowe.
W praktyce oznacza to również mniej problemów związanych z:
- DirectQuery,
- limitem pamięci modeli,
- czasem odświeżania,
- przeciążeniem Power Query.
Czy BigQuery jest opłacalny dla średniej firmy?
To zależy od sposobu wykorzystania danych.
Jeżeli firma:
- generuje niewielkie ilości danych,
- tworzy kilka raportów miesięcznie,
- nie potrzebuje integracji wielu źródeł,
- działa głównie na Excelu,
to wdrożenie BigQuery może być przerostem formy nad treścią.
Natomiast sytuacja zmienia się diametralnie, gdy organizacja:
- rozwija analitykę marketingową,
- buduje e-commerce,
- potrzebuje centralnego repozytorium danych,
- integruje wiele systemów,
- pracuje na dużych zbiorach danych,
- chce rozwijać AI i machine learning.
Wtedy koszt BigQuery często okazuje się niższy niż:
- utrzymanie lokalnej infrastruktury,
- rozbudowa SQL Serverów,
- czas pracy analityków rozwiązujących problemy wydajnościowe,
- chaos organizacyjny wokół danych.
To bardzo ważna perspektywa, ponieważ największym kosztem analityki rzadko jest sama technologia. Najdroższy jest zwykle brak spójności danych i czas ludzi.
Podsumowanie
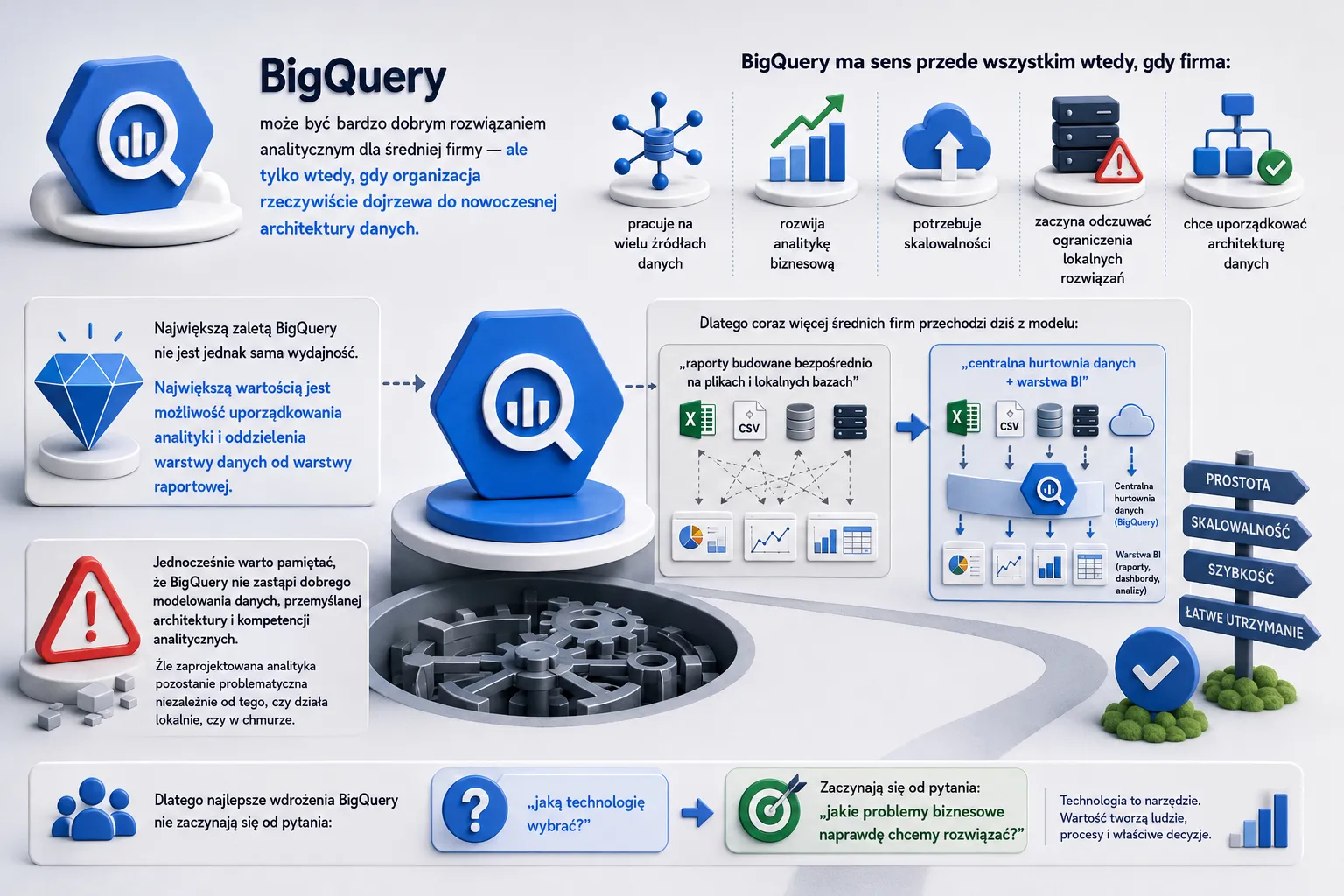
BigQuery może być bardzo dobrym rozwiązaniem analitycznym dla średniej firmy — ale tylko wtedy, gdy organizacja rzeczywiście dojrzewa do nowoczesnej architektury danych.
Nie jest to narzędzie „dla każdego”. Ma sens przede wszystkim wtedy, gdy firma:
- pracuje na wielu źródłach danych,
- rozwija analitykę biznesową,
- potrzebuje skalowalności,
- zaczyna odczuwać ograniczenia lokalnych rozwiązań,
- chce uporządkować architekturę danych.
Największą zaletą BigQuery nie jest jednak sama wydajność. Największą wartością jest możliwość uporządkowania analityki i oddzielenia warstwy danych od warstwy raportowej.
To właśnie dlatego coraz więcej średnich firm przechodzi dziś z modelu:
„raporty budowane bezpośrednio na plikach i lokalnych bazach”
na model:
„centralna hurtownia danych + warstwa BI”.
Jednocześnie warto pamiętać, że BigQuery nie zastąpi dobrego modelowania danych, przemyślanej architektury i kompetencji analitycznych. Źle zaprojektowana analityka pozostanie problematyczna niezależnie od tego, czy działa lokalnie, czy w chmurze.
Dlatego najlepsze wdrożenia BigQuery nie zaczynają się od pytania:
„jaką technologię wybrać?”
Zaczynają się od pytania:
„jakie problemy biznesowe naprawdę chcemy rozwiązać?”

Git dla analityków danych – dlaczego Excel nie wystarcza do kontroli wersji?

SQL w BigQuery – czym różni się od klasycznego SQL?

Ile kosztuje BigQuery w praktyce? Przykładowe wyliczenia

Jakie zapytania SQL są najczęściej używane w pracy analityka?
