


SQL w BigQuery – czym różni się od klasycznego SQL?
BigQuery
SQL
Analityka danych
Spis treści:
- Wstęp
- Architektura BigQuery – dlaczego SQL działa tu inaczej
- SQL w BigQuery vs klasyczny SQL – kluczowe różnice
- Podejście do zapytań – zmiana sposobu myślenia
- Przykład biznesowy – migracja raportowania do BigQuery
- Pułapki i błędy przy pracy z SQL w BigQuery
- Kiedy SQL w BigQuery ma sens (a kiedy nie)
- Podsumowanie – SQL ten sam, ale sposób myślenia inny
Wstęp
Na pierwszy rzut oka SQL w Google BigQuery wygląda znajomo. SELECT, JOIN, GROUP BY – wszystko wydaje się identyczne jak w tradycyjnych bazach danych. I to właśnie jest największa pułapka.
W praktyce BigQuery to nie jest „kolejna baza SQL”. To silnik analityczny działający w chmurze, zaprojektowany pod zupełnie inne założenia: ogromne wolumeny danych, przetwarzanie rozproszone i model kosztowy oparty o zapytania, a nie infrastrukturę.
Z tego wynika kluczowa różnica: SQL w BigQuery nie zmienia się tylko składniowo – zmienia się sposób myślenia o danych.
W tym artykule przeanalizujemy:
- jak działa SQL w BigQuery „pod maską”
- czym różni się od klasycznych baz (np. PostgreSQL, SQL Server)
- jakie są pułapki i dobre praktyki
- kiedy to podejście ma sens, a kiedy nie
Architektura BigQuery – dlaczego SQL działa tu inaczej
Zrozumienie różnic zaczyna się od architektury. W klasycznych bazach danych SQL działa na serwerze, który ma ograniczone zasoby: CPU, RAM, dysk. Optymalizacja zapytań polega na minimalizowaniu obciążenia tej jednej maszyny.
BigQuery działa inaczej – to system rozproszony. Twoje zapytanie jest dzielone na setki lub tysiące równoległych operacji wykonywanych na wielu maszynach jednocześnie.
W praktyce oznacza to:
- nie zarządzasz serwerem – nie interesuje Cię RAM czy CPU
- nie tworzysz indeksów w klasycznym rozumieniu
- optymalizacja polega na minimalizowaniu ilości przetwarzanych danych, a nie „sprytnym użyciu indeksu”
To fundamentalna zmiana. W tradycyjnym SQL pytasz:
👉 „Jak zrobić zapytanie najszybciej?”
W BigQuery pytasz:
👉 „Jak przetworzyć jak najmniej danych?”
Z tego wynika też model kosztowy – płacisz za ilość przetworzonych danych (scan), a nie za czas działania serwera.
SQL w BigQuery vs klasyczny SQL – kluczowe różnice
Na poziomie składni wiele rzeczy wygląda podobnie, ale różnice wychodzą w praktyce.
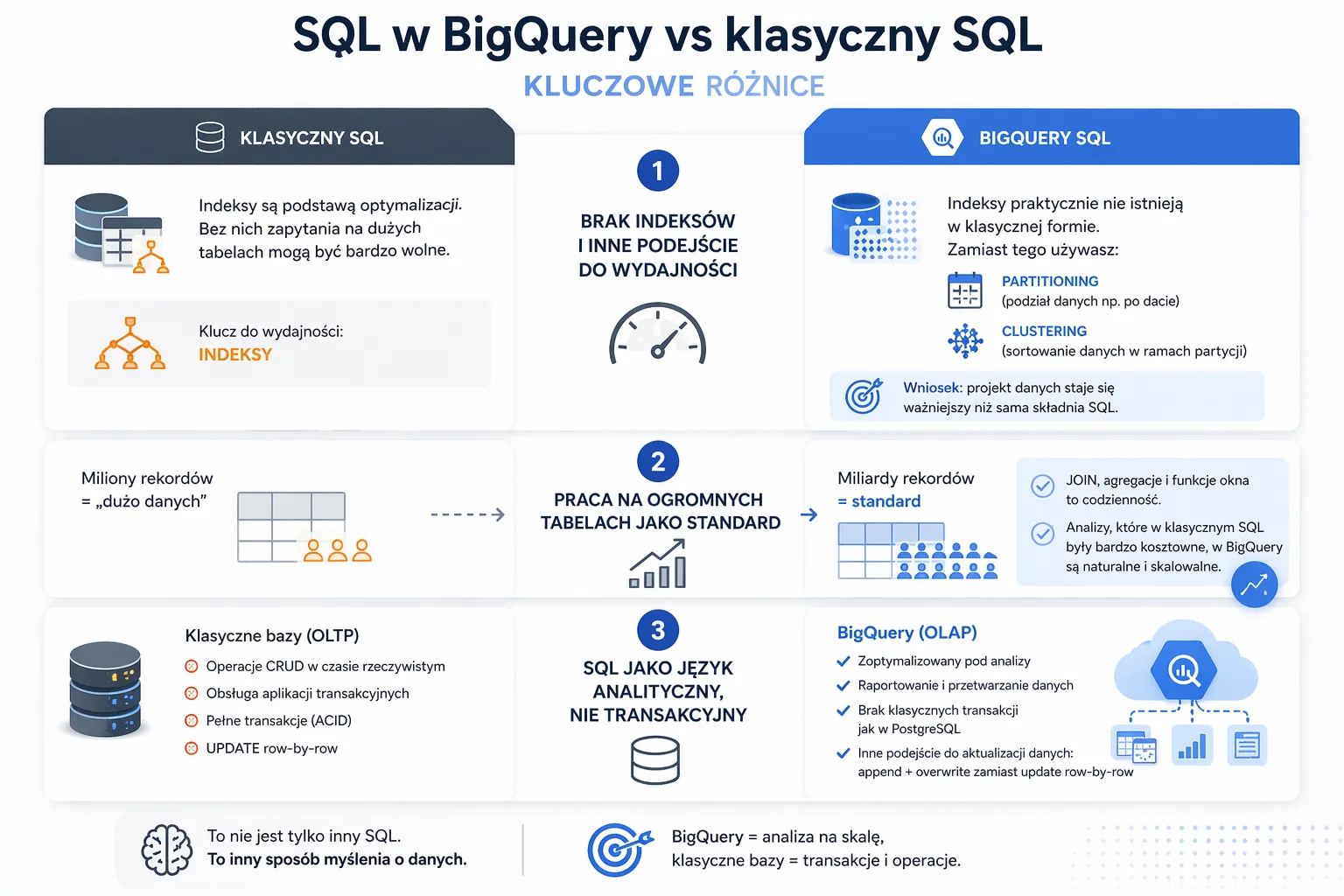
- Brak indeksów i inne podejście do wydajności
W klasycznych bazach indeksy są podstawą optymalizacji. Bez nich zapytania na dużych tabelach mogą być bardzo wolne.
W BigQuery:
- indeksy praktycznie nie istnieją w klasycznej formie
- zamiast tego używasz:
- partitioningu (podział danych np. po dacie)
- clusteringu (sortowanie danych w ramach partycji)
To oznacza, że projekt danych staje się ważniejszy niż sama składnia SQL.
- Praca na ogromnych tabelach jako standard
W tradycyjnych systemach:
- miliony rekordów = „dużo danych”
W BigQuery:
- miliardy rekordów = standard
To zmienia podejście do zapytań. Operacje typu JOIN czy agregacje nie są wyjątkiem – są codziennością.
Co więcej, BigQuery świetnie radzi sobie z analizami, które w klasycznym SQL byłyby bardzo kosztowne – np. funkcje okna (window functions), o których szerzej mowa również w kontekście klasycznego SQL .
- SQL jako język analityczny, nie transakcyjny
BigQuery nie jest systemem OLTP. Nie służy do:
- operacji CRUD w czasie rzeczywistym
- obsługi aplikacji transakcyjnych
To silnik OLAP – zoptymalizowany pod:
- analizy
- raportowanie
- przetwarzanie danych
Z tego wynika m.in.:
- brak klasycznych transakcji jak w PostgreSQL
- inne podejście do aktualizacji danych (append + overwrite zamiast update row-by-row)
Podejście do zapytań – zmiana sposobu myślenia
Największa różnica nie leży w składni, tylko w sposobie projektowania zapytań.
W klasycznym SQL optymalizujesz:
- joiny
- indeksy
- execution plan
W BigQuery kluczowe jest:
- ile danych skanujesz
- czy filtrujesz dane na wczesnym etapie
- czy używasz odpowiednich partycji
Przykład myślenia
W klasycznym SQL możesz napisać:
SELECT *
FROM sprzedaż
To może być OK, jeśli tabela ma 100 tys. rekordów.
W BigQuery to bardzo zły pomysł.
Dlaczego?
- skanujesz całą tabelę
- płacisz za każdy przetworzony GB danych
Lepsze podejście:
SELECT data, produkt, przychód
FROM sprzedaż
WHERE data >= '2025-01-01′
W praktyce oznacza to:
- mniejszy koszt
- szybsze zapytanie
- lepszą skalowalność
Przykład biznesowy – migracja raportowania do BigQuery
Rozważmy realny scenariusz.
Przykład 1 – firma e-commerce
Kontekst:
Firma e-commerce analizuje dane sprzedażowe w klasycznej bazie SQL Server.
Problem:
- raporty trwają kilkanaście minut
- baza zaczyna się „dusić” przy rosnącej liczbie danych
- BI (np. Power BI) działa wolno
Rozwiązanie:
Migracja danych do BigQuery i zmiana zapytań:
- zamiast liczyć agregacje w narzędziu BI → liczenie w SQL (BigQuery)
- zamiast pobierać surowe dane → agregaty na poziomie dnia / produktu
Efekt:
- raporty generują się w kilka sekund
- spadek obciążenia narzędzi BI
- większa kontrola nad logiką analityczną
To dokładnie podejście, które często okazuje się bardziej efektywne niż „przerzucanie” logiki do warstwy wizualizacji – co jest częstą pułapką w klasycznych rozwiązaniach.
Pułapki i błędy przy pracy z SQL w BigQuery
Mimo że BigQuery jest bardzo potężny, łatwo popełnić błędy – szczególnie przy migracji z klasycznych baz.
Najczęstsze problemy:
- *„SELECT ” na dużych tabelach
Generuje ogromne koszty i niepotrzebne przetwarzanie danych. - Brak partycjonowania danych
Powoduje skanowanie całej tabeli nawet dla prostych zapytań. - Myślenie transakcyjne zamiast analitycznego
Próba używania BigQuery jak OLTP kończy się problemami wydajnościowymi. - Przenoszenie logiki 1:1 z klasycznego SQL
To często działa… ale jest nieefektywne kosztowo.
Kiedy SQL w BigQuery ma sens (a kiedy nie)
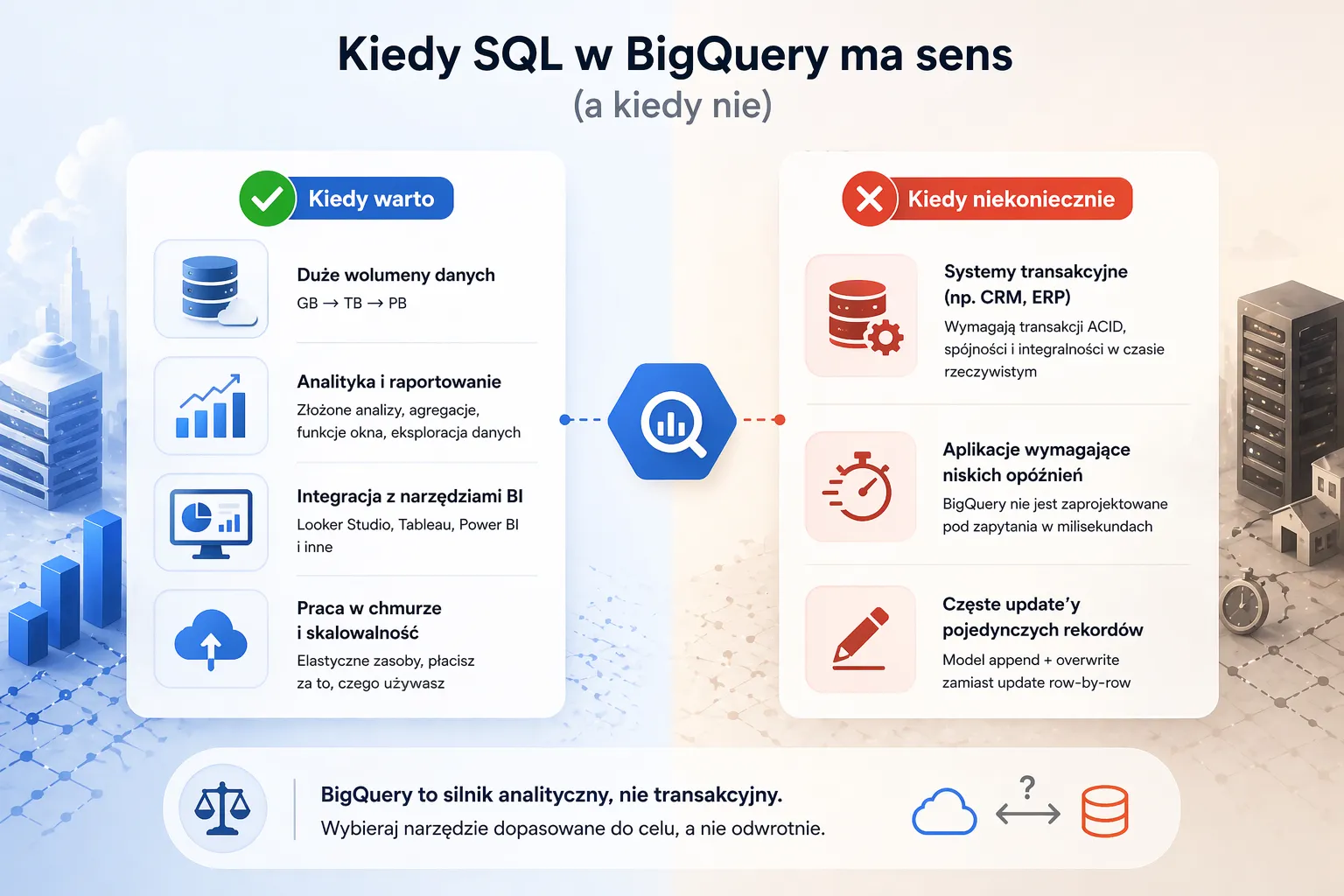
BigQuery nie jest rozwiązaniem uniwersalnym.
Kiedy warto:
- duże wolumeny danych (GB → TB → PB)
- analityka i raportowanie
- integracja z narzędziami BI
- praca w chmurze i skalowalność
Kiedy niekoniecznie:
- systemy transakcyjne (np. CRM, ERP)
- aplikacje wymagające niskich opóźnień
- częste update’y pojedynczych rekordów
Podsumowanie – SQL ten sam, ale sposób myślenia inny
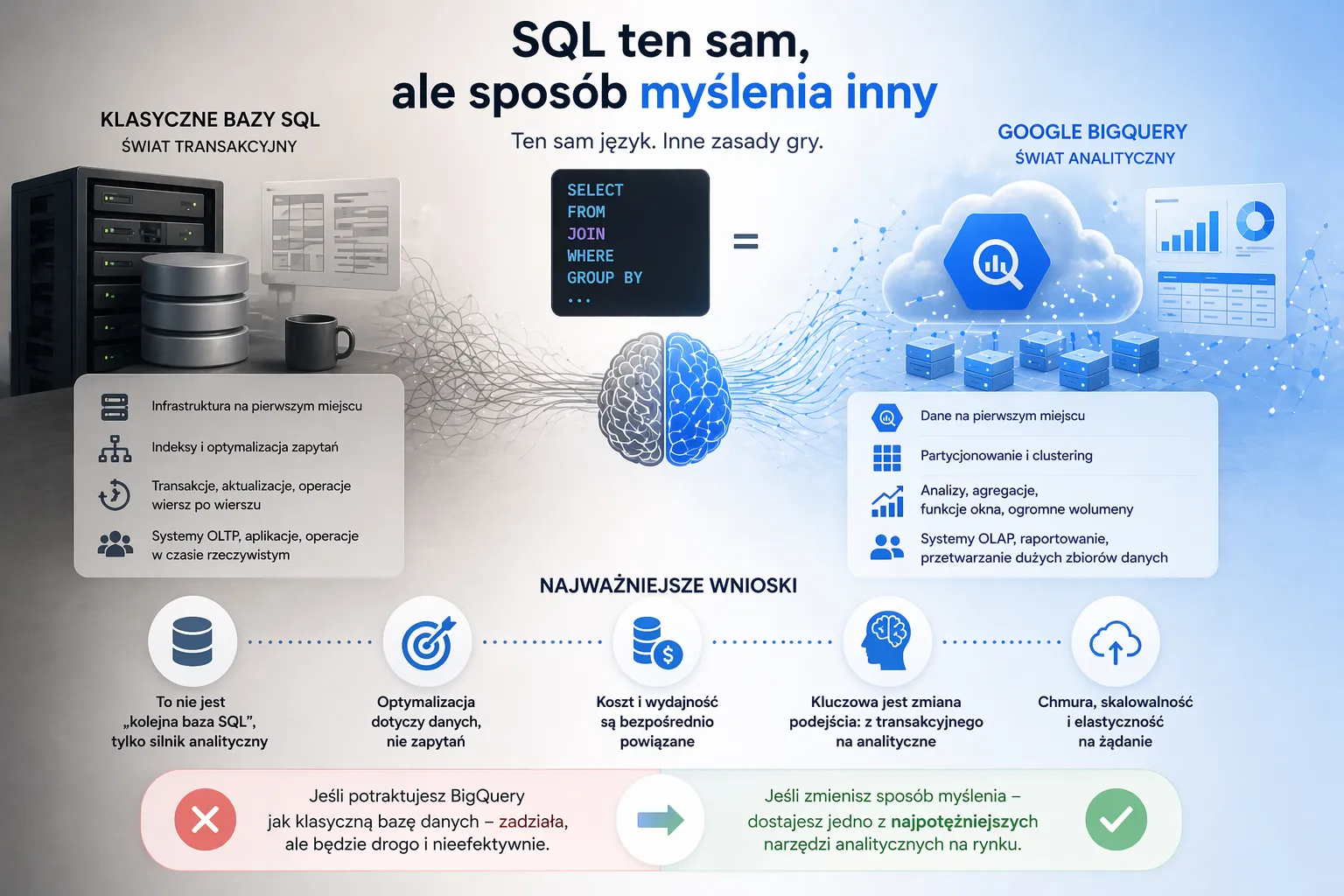
SQL w BigQuery wygląda znajomo, ale działa według zupełnie innych zasad.
Najważniejsze wnioski:
- to nie jest „kolejna baza SQL”, tylko silnik analityczny
- optymalizacja dotyczy danych, nie zapytań
- koszt i wydajność są bezpośrednio powiązane
- kluczowa jest zmiana podejścia: z transakcyjnego na analityczne
Jeśli potraktujesz BigQuery jak klasyczną bazę danych – zadziała, ale będzie drogo i nieefektywnie.
Jeśli zmienisz sposób myślenia – dostajesz jedno z najpotężniejszych narzędzi analitycznych dostępnych na rynku.

Git dla analityków danych – dlaczego Excel nie wystarcza do kontroli wersji?

Czy BigQuery to dobre rozwiązanie analityczne dla średniej firmy?

Window Functions w SQL – niedoceniane narzędzie analityka

Ile kosztuje BigQuery w praktyce? Przykładowe wyliczenia
